*[English](README.md) ∙ [日本語](README-ja.md) ∙ [简体中文](README-zh-Hans.md) ∙ [繁體中文](README-zh-TW.md) | [العَرَبِيَّة](https://github.com/donnemartin/system-design-primer/issues/170) ∙ [বাংলা](https://github.com/donnemartin/system-design-primer/issues/220) ∙ [Português do Brasil](https://github.com/donnemartin/system-design-primer/issues/40) ∙ [Deutsch](https://github.com/donnemartin/system-design-primer/issues/186) ∙ [ελληνικά](https://github.com/donnemartin/system-design-primer/issues/130) ∙ [עברית](https://github.com/donnemartin/system-design-primer/issues/272) ∙ [Italiano](https://github.com/donnemartin/system-design-primer/issues/104) ∙ [한국어](https://github.com/donnemartin/system-design-primer/issues/102) ∙ [فارسی](https://github.com/donnemartin/system-design-primer/issues/110) ∙ [Polski](https://github.com/donnemartin/system-design-primer/issues/68) ∙ [русский язык](https://github.com/donnemartin/system-design-primer/issues/87) ∙ [Español](https://github.com/donnemartin/system-design-primer/issues/136) ∙ [ภาษาไทย](https://github.com/donnemartin/system-design-primer/issues/187) ∙ [Türkçe](https://github.com/donnemartin/system-design-primer/issues/39) ∙ [tiếng Việt](https://github.com/donnemartin/system-design-primer/issues/127) ∙ [Français](https://github.com/donnemartin/system-design-primer/issues/250) | [Add Translation](https://github.com/donnemartin/system-design-primer/issues/28)*
**עזרו [לתרגם](TRANSLATIONS.md) את המדריך!**
# המדריך לתכנון מערכות (The System Design Primer)

## מוטיבציה
> ללמוד איך לתכנן מערכות ב-scale גדול.
>
> להתכונן לראיונות ארכיטקטורה.
### ללמוד איך לתכנן מערכות ב-scale גדול
ללמוד כיצד לתכנן מערכות סְקֵילָבִּילִיוּת יסייע לך להפוך למהנדס תוכנה טוב יותר.
תכנון מערכות הוא נושא רחב. יש **כמות אדירה של משאבים ברחבי הרשת** על עקרונות של תכנון מערכות.
ה-repo הזה הוא **אוסף מסודר** של משאבים שנועדו לעזור לך ללמוד איך לבנות מערכות ב-scale.
### ללמוד מקהילת הקוד הפתוח
מדובר בפרויקט קוד פתוח (open source) שמתעדכן באופן מתמשך.
מוזמנים [לתרום!](#contributing)
### להתכונן לראיונות ארכיטקטורה
בנוסף לראיונות קידוד, ארכיטקטורה היא **רכיב נדרש** כחלק מתהליך **ראיונות טכניים** בהרבה חברות טכנולוגיות.
**תוכל לתרגל שאלות ארכיטקטורה נפוצות** ואף **להשוות** את התוצאות שלך עם **פתרונות לדוגמה**: דיונים, קוד, ודיאגרמות.
### נושאים נוספים להכנה לראיונות:
החבילות המוכנות של כרטיסיות [Anki](https://apps.ankiweb.net/) משתמשות בשיטת **חזרתיות מבוססת מרווחים (Spaced Repetition)** כדי לעזור לך לזכור מושגים חשובים בתכנון מערכות.
מומלצות לשימוש בדרכים.
### משאב לראיונות קידוד: אתגרי קידוד אינטראקטיביים
מחפש משאבים שיעזרו לך להתכונן [**לראיונות קידוד**](https://github.com/donnemartin/interactive-coding-challenges)?
תעיף מבט על ה-repo המקביל [**Interactive Coding Challenges**](https://github.com/donnemartin/interactive-coding-challenges), שמכיל חבילת Anki נוספת:
## תרומה למדריך
> ללמוד מהקהילה.
אל תהסס להגיש pull requests כדי לעזור:
תכנים שעדיין דורשים ליטוש מסומנים בתור
תחת פיתוח.
מומלץ לעיין ב
הנחיות לתרומה לפני התחלה.
> סיכומים של נושאים שונים בתכנון מערכות, כולל יתרונות וחסרונות. **כל החלטה כוללת פשרות (trade-offs)**.
>
> כל חלק מכיל קישורים להרחבה וללמידה מעמיקה יותר.
אינדקס נושאים
> נושאים מוצעים ללימוד לפי לוח הזמנים לריאיון שלך (קצר, בינוני, ארוך)

**ש: עבור הראיונות, האם אני אמור לדעת כל מה שכתוב כאן?**
**ת: לא, אתה לא צריך לדעת הכול כדי להתכונן לריאיון**.
מה שאתה תישאל עליו בריאיון תלוי בדברים כגון:
- כמה ניסיון יש לך
- מה הרקע הטכני שלך
- לאילו משרות אתה מתראיין
- באילו חברות אתה מתראיין
- מזל
לרוב מצופה ממועמדים מנוסים יותר לדעת יותר על ארכיטקטורה ותכנון מערכות. ארכיטקטים או ראשי צוותים מצופים לדעת יותר מאשר עובדים בודדים. חברות טכנולוגיות מובילות לרוב יערכו ריאיון אחד או יותר של ארכיטקטורה.
רצוי להתחיל רחב ולהעמיק במספר תחומים. זה עוזר לדעת קצת בנוגע למספר נושאי מפתח בתכנון מערכות. תתאים את המדריך לפי לוח הזמן שלך, הניסיון, המשרות שאתה מתראיין אליהן, והחברות שבהן אתה מתראיין.
- לוח זמנים קצר – התמקד ברוחב של נושאים בתכנון מערכות. תרגל פתרון של כמה שאלות ריאיון.
- לוח זמנים בינוני – התמקד ברוחב וקצת עומק של נושאים בתכנון מערכות. תרגל פתרון של הרבה שאלות ריאיון.
- לוח זמנים ארוך – התמקד ברוחב ויותר עומק של נושאים בתכנון מערכות. תרגל פתרון של רוב שאלות הריאיון.
> איך לפתור שאלת ראיון ארכיטקטורה.
ראיון ארכיטקטורה הוא **שיחה פתוחה**. מצופה ממך להוביל אותה.
אתה יכול להיעזר בצעדים הבאים כדי להנחות את הדיון. כדי לחזק את ההבנה של התהליך, תעבור על [שאלות ריאיון בתכנון מערכות עם פתרונות](#system-design-interview-questions-with-solutions) אל מול הצעדים הבאים:
### תאר מקרי שימוש, אילוצים והנחות עבודה
אסוף דרישות והגדר את ה-scope של הבעיה.
שאל שאלות כדי להבהיר את מקרי השימוש והאילוצים. דון בהנחות העבודה שאתה עושה.
- מי הולך להשתמש במערכת?
- איך הם הולכים להשתמש בה?
- כמה משתמשים יהיו?
- מה המערכת עושה?
- מה הקלטים והפלטים של המערכת?
- בכמה דאטא נצטרך לטפל?
- כמה בקשות לשניה מחכות לנו?
- מה היחס הצפוי בין קריאה לכתיבה?
### שלב 2: כתוב תכנון במבט על (high level design)
כתוב תכנון high level עם כל הרכיבים החשובים.
- שרטט את הרכיבים החשובים והקשרים ביניהם
- תצדיק את הרעיונות שלך
### שלב 3: תכנן את הרכיבים המרכזיים
צלול לפרטים של כל רכיב מרכזי. לדוגמה, אם התבקשת לתכנן [שירות קיצור כתובות url](solutions/system_design/pastebin/README.md), דון בנושאים הבאים:
- יצירה ואחסון hash של ה-url המלא
- דרכים כמו MD5 ו-Base62
- התנגשויות hash
- מסד נתונים SQL או NoSQL
- סכמת הנתונים
- המרה של כתובת מקוצרת לכתובת המלאה
- תכנון API ותכנון מונחה עצמים
### שלב 4: תבצע scale לתכנון
זהה וטפל בצווארי בקבוק, בהתאם לאילוצים. למשל, האם תזדקק לאחד מהפתרונות הבאים כדי להתמודד עם בעיות של סקילביליות?
- מאזן עומסים (Load balancer)
- סקיילינג אופקי (Horizontal scaling)
- שמירה במטמון (Caching)
- פיצול בסיס נתונים (Database sharding)
דון בפתרונות אפשריים וה-trade-offs. הכול הוא trade-off. התמודד עם צווארי בקבוק בעזרת [עקרונות תכנון מערכת סקילבילית](#index-of-system-design-topics).
### חישובים "על גב המעטפה" (מהירים)
ייתכן שיבקשו ממך לבצע הערכות באופן ידני. ראה את [הנספח](#appendix) עבור המשאבים הבאים:
* [Use back of the envelope calculations](http://highscalability.com/blog/2011/1/26/google-pro-tip-use-back-of-the-envelope-calculations-to-choo.html)
* [Powers of two table](#powers-of-two-table)
* [Latency numbers every programmer should know](#latency-numbers-every-programmer-should-know)
### מקורות לקריאה נוספת
עיין בקישורים הבאים כדי להבין טוב יותר למה לצפות:
* [How to ace a systems design interview](https://www.palantir.com/2011/10/how-to-rock-a-systems-design-interview/)
* [The system design interview](http://www.hiredintech.com/system-design)
* [Intro to Architecture and Systems Design Interviews](https://www.youtube.com/watch?v=ZgdS0EUmn70)
* [System design template](https://leetcode.com/discuss/career/229177/My-System-Design-Template)
> שאלות נפוצות בריאיון ארכיטקטורה עם הסברים לדוגמה, קוד, ודיאגרמות.
>
> הפתרונות מפנים לתוכן שנמצא בתיקיית `solutions/`.
| שאלה |
פתרון |
| תכנן את pastebin.com (או bit.ly) |
פתרון |
| תכנן את ציר הזמן והחיפוש של טוויטר (או הפיד והחיפוש של פייסבוק) |
פתרון |
| תכנן web crawler |
פתרון |
| תכנן את Mint.com |
פתרון |
| תכנן את מבני הנתונים של רשת חברתית |
פתרון |
| תכנן אחסון key-value למנוע חיפוש |
פתרון |
| תכנן את מנגנון דירוג המכירות לפי קטגוריה של אמזון |
פתרון |
| תכנן מערכת שיכולה לגדול למיליוני משתמשים על AWS |
פתרון |
| הוסף שאלה לתכנון מערכת |
תרום |
### תכנן את pastebin.com (או bit.ly)
[צפה בתרגיל ובפתרון](solutions/system_design/pastebin/README.md)
הצג/הסתר דיאגרמה

### תכנן את ציר הזמן והחיפוש של טוויטר (או הפיד והחיפוש של פייסבוק)
[צפה בתרגיל ובפתרון](solutions/system_design/twitter/README.md)
הצג/הסתר דיאגרמה
### תכנן web crawler
[צפה בתרגיל ובפתרון](solutions/system_design/web_crawler/README.md)
הצג/הסתר דיאגרמה

### תכנן את Mint.com
[צפה בתרגיל ובפתרון](solutions/system_design/mint/README.md)
הצג/הסתר דיאגרמה

### תכנן את מבני הנתונים של רשת חברתית
[צפה בתרגיל ובפתרון](solutions/system_design/social_graph/README.md)
הצג/הסתר דיאגרמה

### תכנן אחסון key-value למנוע חיפוש
[צפה בתרגיל ובפתרון](solutions/system_design/query_cache/README.md)
הצג/הסתר דיאגרמה

### תכנן את מנגנון דירוג המכירות לפי קטגוריה של אמזון
[צפה בתרגיל ובפתרון](solutions/system_design/sales_rank/README.md)
הצג/הסתר דיאגרמה

### תכנן מערכת שיכולה לגדול למיליוני משתמשים על AWS
[צפה בתרגיל ובפתרון](solutions/system_design/scaling_aws/README.md)
הצג/הסתר דיאגרמה
> שאלות נפוצות בתכנון מונחה עצמים עם הסברים לדוגמה, קוד, ודיאגרמות.
>
> הפתרונות מפנים לתוכן שנמצא בתיקיית `solutions/`.
>**הערה: החלק הזה עדיין בפיתוח**
| שאלה |
פתרון |
| תכנן Hash Map |
פתרון |
| תכנן מנגנון Cache בשיטת Least Recently Used |
פתרון |
| תכנן מרכז שירות טלפוני (Call Center) |
פתרון |
| תכנן חפיסת קלפים |
פתרון |
| תכנן חניון |
פתרון |
| תכנן שרת צ'אט |
פתרון |
| תכנן מערך מעגלי |
תרום |
| הוסף שאלה בעיצוב מונחה עצמים |
תרום |
חדש בתחום תכנון מערכות?
ראשית, תצטרך לקבל הבנה בסיסית של העקרונות הנפוצים, ללמוד מה הם, איך משתמשים בהם, מה היתרונות והחסרונות של כל אחד מהם.
### שלב 1: צפה בהרצאה על סקילביליות
[Scalability Lecture at Harvard](https://www.youtube.com/watch?v=-W9F__D3oY4)
* Topics covered:
* Vertical scaling
* Horizontal scaling
* Caching
* Load balancing
* Database replication
* Database partitioning
### שלב 2: קרא מאמר על סקילביליות
[Scalability](https://web.archive.org/web/20221030091841/http://www.lecloud.net/tagged/scalability/chrono)
* Topics covered:
* [Clones](https://web.archive.org/web/20220530193911/https://www.lecloud.net/post/7295452622/scalability-for-dummies-part-1-clones)
* [Databases](https://web.archive.org/web/20220602114024/https://www.lecloud.net/post/7994751381/scalability-for-dummies-part-2-database)
* [Caches](https://web.archive.org/web/20230126233752/https://www.lecloud.net/post/9246290032/scalability-for-dummies-part-3-cache)
* [Asynchronism](https://web.archive.org/web/20220926171507/https://www.lecloud.net/post/9699762917/scalability-for-dummies-part-4-asynchronism)
### השלבים הבאים
בהמשך, נסתכל על trade-offs ב-high level:
* **Performance** vs **scalability**
* **Latency** vs **throughput**
* **Availability** vs **consistency**
נזכור כי **הכול זה trade-off**.
לאחר מכן נצלול לנושאים ספציפיים יותר כמו DNS, CDN ו-load balancers.
## ביצועים (Performance) מול סקילביליות (Scalability)
שירות הוא **סקילבילי (scalable)** אם הוא משתפר **בביצועים (performance)** שלו באופן פרופורציונלי למשאבים שנוספו. באופן כללי, שיפור בביצועים פירושו היכולת לתת שירות ליותר יחידות עבודה, אך הוא יכול גם לבוא לידי ביטוי ביכולת להתמודד עם יחידות עבודה גדולות יותר, ככל שהדאטא גדל.
1
דרך נוספת להסתכל על ביצועים מול סקילביליות
- אם יש לך בעיית ביצועים, המערכת איטית עבור משתמש בודד.
- אם יש לך בעיית סקילביליות, המערכת מהירה עבור משתמש בודד אך איטית בעומס כבד.
### מקורות וקריאה נוספת
* [A word on scalability](http://www.allthingsdistributed.com/2006/03/a_word_on_scalability.html)
* [Scalability, availability, stability, patterns](http://www.slideshare.net/jboner/scalability-availability-stability-patterns/)
**שיהוי** הוא הזמן שנדרש כדי לבצע פעולה כלשהי או להפיק תוצאה כלשהי
**תפוקה** היא מספר הפעולות או התוצאות ליחידת זמן.
באופן כללי, כדאי לשאוף **לתפוקה מקסימלית** עם **שיהוי סביר**.
### חומרים וקריאה נוספת
* [Understanding latency vs throughput](https://community.cadence.com/cadence_blogs_8/b/fv/posts/understanding-latency-vs-throughput)
## זמינות (Availability) מול עקביות (Consistency)
### משפט CAP
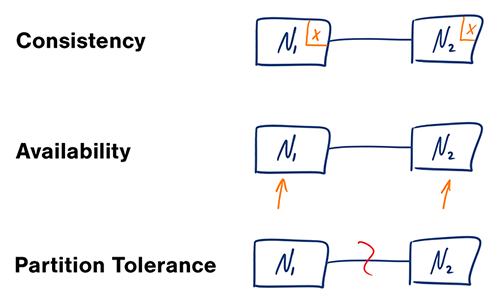
Source: CAP theorem revisited
במערכות מחשוב מבוזרות, ניתן לתמוך רק בשניים מתוך שלושת התנאים הבאים:
- עקביות (Consistency) – כל קריאה מקבלת את הכתיבה העדכנית ביותר, או שגיאה.
- זמינות (Availability) - כל בקשה תקבל מענה, ללא הבטחה שהמידע שיחזור יהיה העדכני ביותר.
- יכולת חלוקה (Partition Tolerance) - המערכת ממשיכה לתפקד גם במקרים בהם נאבדות או מתעכבות מספר הודעות בין שרתי המערכת בגלל בעיות תקשורת.
*ניתן לצאת מנקודת הנחה שרשתות לא אמינות - כך שנהיה חייבים לתמוך ב-״Partition tolerance״.
לכן, נצטרך לבחור אחד משני האחרים - זמינות או עקביות.*
#### בחירה ב-CP - עקביות ויכולת חלוקה
המתנה לתשובה מהמערכת (אשר סובלת מ-network partition) עלולה להסתיים בשגיאת timeout. לכן, CP הוא בחירה טובה במידה ויש הצדקה עסקית לקריאות וכתיבות אטומיות.
#### בחירה ב-AP - זמינות ויכולת חלוקה
תשובות לבקשות מהמערכת מחזירות את הגרסה הזמינה ביותר של הנתונים הזמינים בשרת הרלוונטי, שאינה בהכרח האחרונה. כתיבה עשויה לקחת זמן מסוים עד שתסתיים, עד אשר התקשורת הבעייתית תיפתר.
לכן, AP הוא בחירה טובה במידה ויש הצדקה עסקית לעבוד במצב של [eventual consistency](#eventual-consistency) או במידה והמערכת צריכה להמשיך לשרת למרות שגיאות בלתי-תלויות.
### חומרים וקריאה נוספת
* [CAP theorem revisited](http://robertgreiner.com/2014/08/cap-theorem-revisited/)
* [A plain english introduction to CAP theorem](http://ksat.me/a-plain-english-introduction-to-cap-theorem)
* [CAP FAQ](https://github.com/henryr/cap-faq)
* [The CAP theorem](https://www.youtube.com/watch?v=k-Yaq8AHlFA)
כאשר קיימים מספר עותקים של אותם נתונים, עלינו להחליט כיצד לסנכרן ביניהם כדי שלקוחות יקבלו תצוגה עקבית של המידע.
ניזכר בהגדרה של עקביות מתוך [משפט CAP](#cap-theorem): כל קריאה מקבלת את הכתיבה העדכנית ביותר או שגיאה.
### עקביות חלשה (Weak Consistency)
לאחר כתיבה, קריאות עשויות לראות או לא לראות את הערך החדש שנכתב. הגישה כאן היא של best effort - המאמץ הטוב ביותר.
גישה זו נפוצה במערכות כמו memcached. עקביות חלשה מתאימה למקרים של מערכות זמן-אמת, כמו VoIP, שיחות וידאו, ומשחקים מרובי משתתפים.
לדוגמה, אם אתה בשיחת טלפון ומאבד קליטה לכמה שניות, כשאתה חוזר אתה לא שומע מה שנאמר בזמן שלא הייתה קליטה.
### עקביות לא מיידית (Eventual Consistency)
לאחר כתיבה, הקריאות יראו בסופו של דבר את מה שנכתב (בדרך כלל תוך מספר מילישניות). הנתונים משוכפלים באופן אסינכרוני.
גישה זו נפוצה במערכות כמו DNS ומייל. עקביות לא מיידית מתאימה למערכות ששומרות על זמינות גבוהה במיוחד.
### עקביות חזקה (Strong Consistency)
לאחר כתיבה, הקריאות יראו תמיד את הערך החדש שנכתב. השכפול מתבצע באופן סינכרוני.
גישה זו נפוצה במערכות קבצים ובמסדי נתונים רלציוניים (RDBMS). עקביות חזקה מתאימה למערכות שדורשות טרנזקציות.
### מקורות וקריאה נוספת
- [Transactions across data centers](http://snarfed.org/transactions_across_datacenters_io.html)
## דפוסי זמינות (Availability Patterns)
קיימים שני דפוסים משלימים לתמיכה בזמינות גבוהה: **מעבר אוטומטי (fail-over)** ו-**שכפול (replication)**.
### גיבוי בזמן כישלון (Fail-Over)
#### אקטיבי-פסיבי (Active-Passive)
במבנה אקטיבי-פסיבי, נשלחים heartbeat-ים בין השרת הפעיל לשרת הרזרבי (הפסיבי). אם ה-heartbeat נקטע, השרת הפסיבי לוקח את כתובת ה-IP של הפעיל וממשיך את השירות.
משך זמן ההשבתה תלוי אם השרת הפסיבי פועל מראש במצב 'חם' (hot standby), או שיש להפעילו ממצב 'קר' (cold standby). רק השרת הפעיל מקבל תעבורה.
סוג זה נקרא גם Master-Slave.
#### אקטיבי-אקטיבי (Active-Active)
במבנה אקטיבי-אקטיבי, שני השרתים מקבלים תעבורה ומחלקים ביניהם את העומס.
אם השרתים חשופים פומבית, שרת ה-DNS צריך לדעת על כתובות ה-IP הציבוריות של שניהם. אם השרתים פנימיים, על לוגיקת האפליקציה להכיר את שניהם.
סוג זה נקרא גם Master-Master.
### חסרונות של מעבר אוטומטי
- מעבר אוטומטי מוסיף חומרה ועלות תפעולית.
- קיימת אפשרות לאובדן נתונים אם המערכת הפעילה קורסת לפני שהספיקה לשכפל את המידע למערכת הפסיבית.
### שכפול (Replication)
#### עבור Master-Slave/Master-Master
נושא זה נדון בפירוט נוסף בחלק על [מסדי נתונים](#database):
- [Master-slave replication](#master-slave-replication)
- [Master-master replication](#master-master-replication)
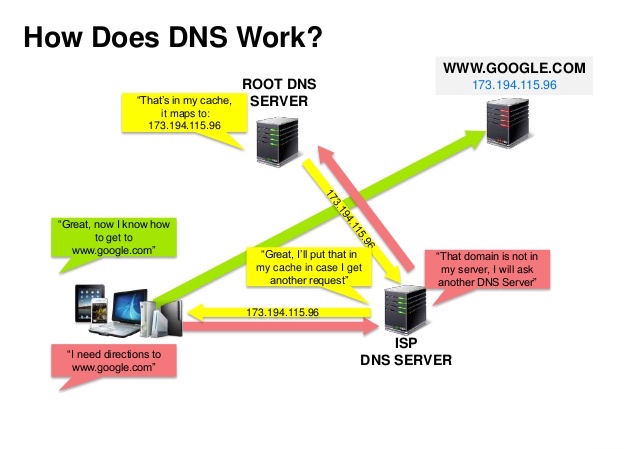
מקור: מצגת אבטחת DNS
מערכת שמות דומיינים (DNS) ממירה שם דומיין כמו `www.example.com` לכתובת IP.
ה-DNS בנוי בהיררכיה: כאשר ישנם כמה שרתי ניהול בשכבה העליונה. ה-router שלך או ספק האינטרנט (ISP) מספקים כתובות לשרת(י) DNS שיש לפנות אליהם בעת ביצוע חיפוש של כתובת.
שרתי DNS בשכבה נמוכה יותר, מבצעים cache למיפויים, שעלולים להיות לא עדכניים (stale) אם הרשומה המעודכנת עוד לא עברה מהשרת בשכבה הגבוהה עד למטה (propagation delays).
המיפוי של ה-DNS יכול להישמר על ידי הדפדפן או מערכת ההפעלה לפרק זמן מסוים, הנקבע על ידי [TTL – Time To Live](https://he.wikipedia.org/wiki/Time_to_live).
- NS record (Name Server) – מגדירה את שרתי DNS עבור הדומיין/תת-דומיין.
- MX record (Mail Exchange) – מגדירה את שרתי הדואר לקבלת הודעות.
- A record (Address) – ממפה שם לכתובת IP.
- CNAME (Canonical Name) – ממפה שם לשם אחר (למשל example.com →
www.example.com) או לרשומת A.
שירותים מנוהלים כמו [CloudFlare](https://www.cloudflare.com/dns/) ו-[Route 53](https://aws.amazon.com/route53/) מספקים DNS מנוהל.
חלקם מאפשרים ניתוב תעבורה בשיטות שונות:
- [Weighted round robin](https://www.jscape.com/blog/load-balancing-algorithms)
- Prevent traffic from going to servers under maintenance
- Balance between varying cluster sizes
- A/B testing
- [Latency-based](https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/routing-policy-latency.html)
- [Geolocation-based](https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/routing-policy-geo.html)
### חסרונות (DNS)
- פנייה לשרת DNS מוסיפה עיכוב קל, אם כי ברוב המקרים הוא מתמתן בזכות caching כפי שתואר קודם.
- ניהול שרתי DNS יכול להיות מורכב, ולרוב מנוהל על-ידי ממשלות, ISPs וחברות גדולות.
- שירותי DNS היו יעד לאחרונה ל-מתקפות DDoS, מה שמנע מגולשים להגיע לאתרים (למשל Twitter) בלי להכיר כתובות IP ידניות.
### מקורות וקריאה נוספת
- [DNS architecture](https://technet.microsoft.com/en-us/library/dd197427(v=ws.10).aspx)
- [Wikipedia](https://en.wikipedia.org/wiki/Domain_Name_System)
- [DNS articles](https://support.dnsimple.com/categories/dns/)
## רשתות הפצת תוכן (CDN)
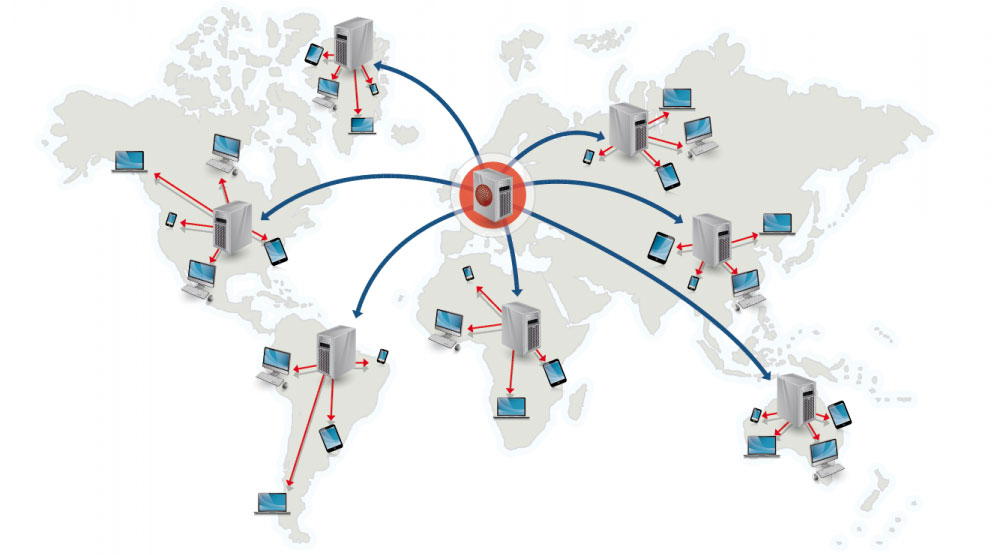
מקור: Why use a CDN
רשת הפצת תוכן (CDN) היא רשת גלובלית ומבוזרת של שרתי proxy, אשר מנגישים תכנים ממיקומים הקרובים יותר למשתמש הקצה.
בדרך כלל, קבצים סטטיים כמו HTML/CSS/JS, תמונות וסרטונים, מונגשים על ידי CDN, למרות שיש כאלו כמו CloudFront של Amazon התומכים גם בתכנים דינמיים.
מיפוי ה-DNS שיתקבל ינחה את הלקוחות לאיזה שרת להתחבר.
הגשת תוכן מ-CDN משפר ביצועים משמעותית בשני אופנים:
- המשתמש מקבל תוכן מ-data center הקרוב אליו פיזית.
- השרתים אינם צריכים לשרת בקשות שה-CDN מספק במקומם.
### דחיפה (Push)
ב-Push CDN התוכן נדחף אל ה-CDN בכל פעם שהוא משתנה בשרת המקור. האחריות על העלאת הקבצים וכתיבת ה-URLs המופנים ל-CDN היא שלך. אתה מגדיר את הזמן שבו פג תוקפו של תוכן מסוים, ומתי הוא מתעדכן.
תוכן מועלה רק כאשר הוא חדש, או עבר שינוי, מה שמפחית תעבורה אבל ממקסם על האחסון. אתרים עם מעט תוכן או תעבורה, או עם תוכן שלא מתעדכן באופן תדיר עובדים טוב עם Push CDN. התוכן נמצא ב-CDN פעם אחת, במקום שישלפו אותו מחדש בתדירות קבועה.
### משיכה (Pull)
ב-Pull CDN התוכן נשלף מהשרת המקור רק כאשר משתמש מבקש אותו לראשונה. הקבצים נשארים בשרת שלך ו-URLs מפנים ל-CDN.
הבקשה הראשונית איטית יותר עד שהקובץ נשמר ב-CDN.
משך הזמן שבו ישאר ה-cache נקבע על-ידי [TTL – Time to Live](https://he.wikipedia.org/wiki/Time_to_live).
ה-Pull CDN חוסך שטח אחסון על ה-CDN, אך עלול ליצור תעבורה מיותרת אם קבצים פגי-תוקף נשלפים שוב לפני ששונו בפועל.
Pull CDN מתאים לאתרים עתירי תעבורה, שכן העומס מתפזר וה-CDN שומר רק קבצים שנדרשו לאחרונה.
### חסרונות (CDN)
- עלויות CDN עשויות להיות משמעותיות בהתאם לנפח התעבורה, אך יש לשקול אותן מול העלויות שהיית משלם ללא CDN.
- תוכן עלול להיות מיושן (stale) אם עודכן לפני שפג תוקף ה-TTL.
- יש צורך לשנות את כתובות ה-URL של תוכן סטטי כך שיפנו אל ה-CDN.
### מקורות וקריאה נוספת
- [Globally distributed content delivery](https://figshare.com/articles/Globally_distributed_content_delivery/6605972)
- [The differences between push and pull CDNs](http://www.travelblogadvice.com/technical/the-differences-between-push-and-pull-cdns/)
- [Wikipedia](https://en.wikipedia.org/wiki/Content_delivery_network)
## מאזן עומסים (Load Balancer)
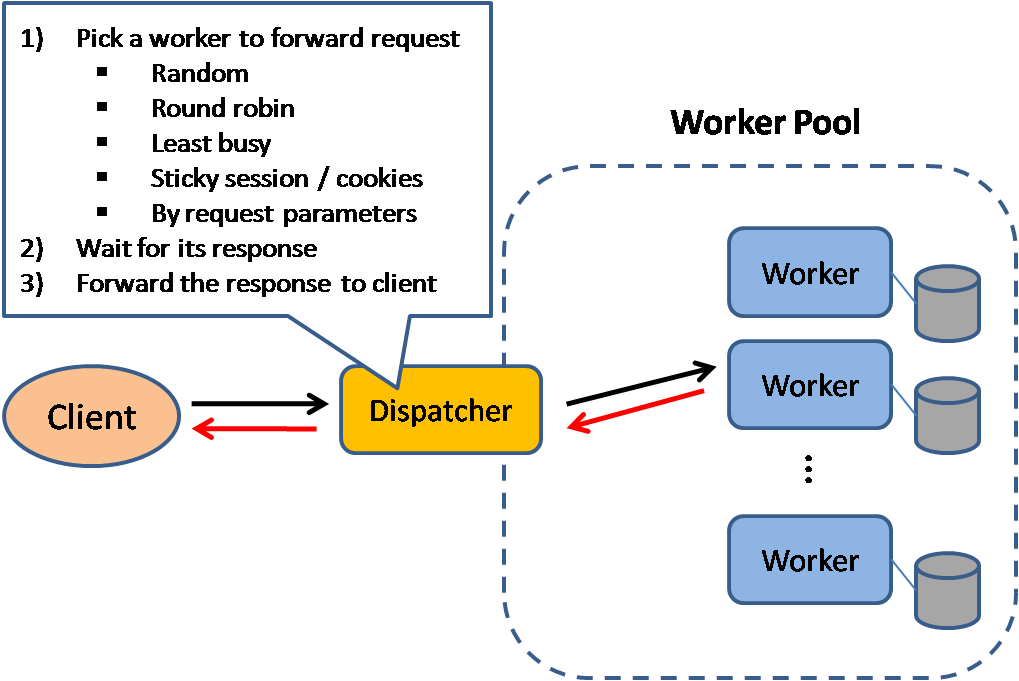
Source: Scalable system design patterns
מאזן עומסים מבזר בקשות נכנסות מלקוח בין משאבי חישוב שונים כגון שרתי אפליקציה ומסדי נתונים. עבור כל בקשה, הוא מחזיר את התשובה ממשאב החישוב המתאים, אל הלקוח המתאים. מאזן עומסים יעיל ב:
- מניעת שליחת בקשות לשרתים לא יציבים (unhealthy)
- מניעת העמסת־יתר על משאבים
- סילוק נקודת כשל בודדת (SPOF)
מאזן עומסים ניתן למימוש כחומרה (יקר) או כתוכנה כדוגמת HAProxy.
יתרונות נוספים:
- SSL Termination – טכניקת אבטחה שבה מפענחים בקשות נכנסות לפני שהן מגיעות לשרת הקצה, ומצפינים את התשובות של השרת כך ששרתי ה-backend לא צריכים לבצע את הפעולות היקרות הללו.
- מוריד את הצורך להתקין תעודות X.509 על כל שרת.
- Session Persistence – יצירת עוגיות (cookies) וניתוב בקשות של לקוח מסוים לאותו מופע שהתנהל מולו, אם האפליקציה לא מנהלת סשנים בעצמה.
כדי להגן מפני כישלונות נהוג להקים מספר מאזני עומסים, במצב
[Active-Passive](#אקטיבי-פסיבי-active-passive) או [Active-Active](#אקטיבי-אקטיבי-active-active).
מאזן עומסים יכול לנתב את התעבורה על פי מדדים שונים:
- Random
- Least loaded
- Session/cookies
- [Round robin or weighted round robin](https://www.g33kinfo.com/info/round-robin-vs-weighted-round-robin-lb)
- [Layer 4](#layer-4-load-balancing)
- [Layer 7](#layer-7-load-balancing)
### איזון עומסים בשכבה 4
מאזני עומסים בשכבה 4 בוחנים מידע בשכבת התעבורה ([transport layer](#communication)) כדי להחליט כיצד להפיץ בקשות.
בדרך כלל, מדובר בכתובות ה-IP של המקור והיעד ובפורטים שבכותרת (header), ולא בתוכן הפקטה (packet).
מאזני עומסים בשכבה 4 מעבירים את חבילות הרשת אל ומן השרת הנבחר (upstream server) תוך ביצוע
[תרגום כתובות רשת (NAT)](https://www.nginx.com/resources/glossary/layer-4-load-balancing/).
### איזון עומסים בשכבה 7
מאזני עומסים בשכבה 7 בוחנים את [שכבת האפליקציה](#communication) כדי להחליט כיצד להפיץ בקשות. ההחלטה יכולה להתבסס על תוכן הכותרות (headers), גוף ההודעה, ועוגיות (cookies).
מאזן עומסים בשכבה 7 מסיים (terminates) את תעבורת הרשת אל מול הלקוח, קורא את ההודעה, מקבל החלטת איזון-עומסים, ואז פותח חיבור לשרת שנבחר.
למשל, מאזן כזה יכול לשלוח תעבורת וידאו לשרתים שמאחסנים קטעי וידאו, ובמקביל לנתב תעבורת חיוב משתמשים (billing) לשרתים מוקשחים אבטחתית.
לעומת זאת, איזון עומסים בשכבה 4 דורש פחות זמן ומשאבי מחשוב מאשר שכבה 7, אם כי על חומרה מודרנית ההשפעה הביצועית עשויה להיות מזערית.
### גדילה אופקית (Horizontal Scaling)
מאזני עומסים מסייעים גם בגדילה אופקית (Horizontal Scaling), וכך משפרים ביצועים וזמינות.
הרחבת המערכת באמצעות שרתים זולים חסכונית יותר ומביאה לרמת זמינות גבוהה לעומת **הגדלה אנכית (Vertical Scaling)** – חיזוק שרת יחיד בחומרה יקרה. בנוסף, קל יותר לגייס אנשי מקצוע המיומנים בעבודה עם שרתים סטנדרטיים מאשר כאלה המתמחים במערכות ארגוניות ייעודיות ויקרות.
#### חסרונות: גדילה אופקית
- גדילה אופקית מוסיפה מורכבות וכוללת שכפול שרתים
- השרתים צריכים להיות stateless: אין לאחסן בהם מידע משתמש כגון סשנים או תמונות פרופיל
- ניתן לשמור סשנים באחסון נתונים מרכזי כגון מסד־נתונים (SQL או NoSQL) או מטמון פרסיסטנטי (Redis, Memcached)
- שרתים בהמשך השרשרת (downstream) למשל cache ו-DB צריכים להתמודד עם יותר חיבורים בו-זמנית ככל שמספר שרתי האפליקציה גדל
### חסרונות: מאזן עומסים
- מאזן העומסים עצמו עלול להפוך לצוואר בקבוק בביצועים אם אין לו מספיק משאבים או אם הוא מוגדר בצורה לא נכונה.
- הוספת מאזן עומסים כדי להסיר נקודת כשל בודדת (SPOF) מוסיפה מורכבות למערכת.
- מאזן עומסים יחיד הוא SPOF, ועבודה עם מספר מאזני עומסים מגדילה עוד יותר את המורכבות.
### מקורות וקריאה נוספת
- [NGINX architecture](https://www.nginx.com/blog/inside-nginx-how-we-designed-for-performance-scale/)
- [HAProxy architecture guide](http://www.haproxy.org/download/1.2/doc/architecture.txt)
- [Scalability](https://web.archive.org/web/20220530193911/https://www.lecloud.net/post/7295452622/scalability-for-dummies-part-1-clones)
- [Wikipedia](https://en.wikipedia.org/wiki/Load_balancing_(computing))
- [Layer 4 load balancing](https://www.nginx.com/resources/glossary/layer-4-load-balancing/)
- [Layer 7 load balancing](https://www.nginx.com/resources/glossary/layer-7-load-balancing/)
- [ELB listener config](http://docs.aws.amazon.com/elasticloadbalancing/latest/classic/elb-listener-config.html)
## פרוקסי הפוך (Reverse Proxy)
פרוקסי הפוך הוא שרת אינטרנט המרכז שירותים פנימיים ומספק ממשק אחיד החוצה. בקשות שמגיעות מלקוחות מועברות לשרת ה-backend המסוגל לטפל בהן, ולאחר מכן הפרוקסי מחזיר ללקוח את תגובת השרת.
יתרונות הכלולים בצורה זו:
- אבטחה מוגברת – הסתרת מידע על שרתי ה-backend, חסימת כתובות IP, הגבלת מספר חיבורים לכל לקוח
- גמישות וסקילביליות מוגברת – הלקוחות רואים רק את כתובת ה-IP של הפרוקסי, מה שמאפשר להגדיל/לשנות שרתים בלי להשפיע על הלקוחות
- SSL Termination – טכניקת אבטחה שבה מפענחים בקשות נכנסות לפני שהן מגיעות לשרת הקצה, ומצפינים את התשובות של השרת כך ששרתי ה-backend לא צריכים לבצע את הפעולות היקרות הללו.
- מוריד את הצורך להתקין תעודות X.509 על כל שרת.
- דחיסה – דחיסת תגובות השרת
- מטמון – החזרת תגובות עבור בקשות שמורות (cached)
- תוכן סטטי – הנגשת קבצים סטטיים ישירות
- קבצי HTML/CSS/JS
- תמונות
- סרטונים
### מאזן עומסים לעומת פרוקסי הפוך
- פריסת מאזן עומסים שימושית כשקיימים מספר שרתים. לרוב הוא מנתב תעבורה לקבוצת שרתים המבצעים אותה לוגיקה.
- פרוקסי הפוך מועיל גם כאשר יש רק שרת אינטרנט/אפליקציה אחד – ומעניק את כל היתרונות שפורטו לעיל.
- פתרונות כמו NGINX ו-HAProxy תומכים גם בפרוקסי הפוך בשכבה 7 וגם באיזון עומסים.
### חסרונות: פרוקסי הפוך
- הכנסת פרוקסי הפוך מוסיפה מורכבות לארכיטקטורה.
- פרוקסי הפוך יחיד הוא SPOF. הגדרת כמה כאלו להפחתת סיכון (Fail-over) מוסיפה מורכבות נוספת.
### מקורות וקריאה נוספת
- [Reverse proxy vs load balancer](https://www.nginx.com/resources/glossary/reverse-proxy-vs-load-balancer/)
- [NGINX architecture](https://www.nginx.com/blog/inside-nginx-how-we-designed-for-performance-scale/)
- [HAProxy architecture guide](http://www.haproxy.org/download/1.2/doc/architecture.txt)
- [Wikipedia](https://en.wikipedia.org/wiki/Reverse_proxy)
הפרדת שכבת הרשת משכבת האפליקציה (ידועה גם כשכבת ה-platform), מאפשרת לבצע scaling ולקנפג את שתי השכבות באופן בלתי תלוי. הוספת API חדש גוררת הוספתי שרתי אפליקציה, מבלי להוסיף בהכרח גם שרתי המטפלים בלוגיקת הרשת.
עקרון האחריות היחידה (**single respoinsibility principle**) מעודד סרביסים עצמאיים וקטנים שעובדים יחד. צוותים קטנים המטפלים שירותים קטנים יכלוים להתכוונן בצורה מיטבית לגדילה מהירה.
Workers בשכבת האפליקציה מסייעים גם [לא-סינכרוניות](#asynchronism).
### מיקרו-סרביסים (Microservices)
במונח [Microservices](https://he.wikipedia.org/wiki/מיקרו-שירותים) הכוונה למערך של שירותים קטנים, מודולריים, הניתנים לפריסה עצמאית. כל שירות רץ כתהליך נפרד ומתקשר באמצעות מנגנון פשוט ומוגדר היטב כדי להשיג יעד עסקי.
1
לדוגמה, ב-Pinterest יכולים להיות המיקרו-סרביסים הבאים: פרופיל משתמש, עוקבים, פיד, חיפוש, העלאת תמונה וכו'.
### גילוי סרביסים (Service Discovery)
מערכות כמו [Consul](https://www.consul.io/docs/index.html), [Etcd](https://coreos.com/etcddocs/latest), ו-[Zookeeper](http://www.slideshare.net/sauravhaloi/introduction-to-apache-zookeeper) מסייעות לשירותים “למצוא” זה את זה על ידי ניהול ומעקב אחר שמות הסרביסים, כתובות IP, ופורטים.
בדיקות דופק ([Health checks](https://www.consul.io/intro/getting-started/checks.html)) — מאמתות את תקינות השירות, לעיתים קרובות באמצעות endpoint HTTP.
גם Consul וגם Etcd כוללים
[אחסון key-value](#key-value-store) מובנה, השימושי לאחסון קונפיגורציה ונתונים משותפים.
### חסרונות: שכבת האפליקציה
- הוספת שכבת אפליקציה עם סרביסים שהקשר ביניהם רופף (loosely coupled) דורשת גישה שונה בארכיטקטורה, תפעול ותהליכי פיתוח (לעומת מערכת מונוליטית).
- מיקרו-סרביסים עלולים להוסיף מורכבות מבחינת פריסות ותפעול.
### מקורות וקריאה נוספת
- [Intro to architecting systems for scale](http://lethain.com/introduction-to-architecting-systems-for-scale)
- [Crack the system design interview](http://www.puncsky.com/blog/2016-02-13-crack-the-system-design-interview)
- [Service oriented architecture](https://en.wikipedia.org/wiki/Service-oriented_architecture)
- [Introduction to Zookeeper](http://www.slideshare.net/sauravhaloi/introduction-to-apache-zookeeper)
- [Here's what you need to know about building microservices](https://cloudncode.wordpress.com/2016/07/22/msa-getting-started/)