18 KiB
Pastebin.com (or Bit.ly) のデザイン
Note: このドキュメントは、重複を避けるために、システム設計入門にある関連領域に直接リンクしています。一般的な話のポイントやトレードオフ, 代替案についてはリンク先を参照して下さい。
Bit.ly のデザイン - Pastebin が元の短縮されていない URL ではなくて paste の内容を求める点を除けば、同様の質問です。
Step 1: ユースケースと制約の概要
要件を収集し、問題の範囲を調べて下さい。 ユースケースと制約を明確にするために質問して下さい。 仮定について議論して下さい。
明確化するための質問に応えるインタビュアーが不在の場合は、自発的にユースケースや制約を定義しましょう。
ユースケース
以下のユースケースのみを処理するために、問題のスコープを定義します
- User は、テキストブロックを入力し、ランダムに生成されたリンクを取得します
- 有効期限
- デフォルト設定では期限切れしません
- 任意に、有効期限を設定できます
- 有効期限
- User は、ペーストされた URL を入力して内容を閲覧できます
- User は匿名です
- Service は、ページの分析を追跡します
- 毎月の訪問統計
- Service は、期限切れのペーストを削除します
- Service は、高可用性があります
問題のスコープ外
- User がアカウント登録する
- User がメールを確認する
- User が登録済みアカウントにログインする
- User がドキュメントを編集する
- User が可視性を設定できる
- User が shortlink を設定できる
制約と仮定
状態の仮定
- トラフィックは均等に分散されていない
- shortlink を辿るのははやい
- ペーストはテキストのみ
- ページの閲覧分析はリアルタイムである必要が無い
- 1千万人のユーザ
- 1ヶ月あたり、1千万回の Write
- 1ヶ月あたり、1億回の Read
- Read と Write の比率が、 10 : 1
使用量の計算
大雑把な使用量の計算をする必要がある場合は、インタビュアーにそれを伝えて下さい。
- ペーストあたりのサイズ
- 1 KB / paste
shortlink- 7 bytesexpiration_length_in_minutes- 4 bytescreated_at- 5 bytespaste_path- 255 bytes- total = ~1.27 KB
- 1ヶ月あたりの新しいペーストサイズは 12.7 GB
- 1.27 KB * 1千万回/月
- 3年間で最大 450 GBの新しいペースト
- 3年間で3億6千万のショートリンク
- ほとんどが既存のものへの更新ではなく、新しいペーストであると仮定する
- 平均して 4 paste write/sec
- 平均して 40 read/sec
便利な変換ガイド:
- 1ヶ月は約250万秒
- 1 req/sec = 250万 req/month
- 40 req/sec = 100万 req/month
- 400 req/sec = 10億 req/month
Step 2: 高レベルデザインの作成
全ての重要なコンポーネントを含んだ、高レベルな設計の概要を説明します。

Step 3: コアコンポーネントを設計する
各コンポーネントの詳細に踏み込みます。
ユースケース: User は、テキストブロックを入力し、ランダムに生成されたリンクを取得します
リレーショナルデータベースを大きなハッシュテーブルとして使用し、生成された URL をファイルサーバと貼り付けファイルを含むパスにマッピングできます。
ファイルサーバを使用する代わりに, Amazon S3 や NoSQL ドキュメントストアといったオブジェクトストアを使用できます。
大きなハッシュテーブルとして機能するリレーショナルデータベースの代わりに, NoSQL key-value ストアを使用できます。 SQL と NoSQL のどちらを選択するかのトレードオフについて議論する必要があります。 以下の説明では、リレーショナルデータベースのアプローチを採っています。
- Client は、reverse proxy として動いている Web Server にペーストリクエストを送ります。
- Web Server は、リクエストを Write API サーバに転送します
- Write API サーバは以下のことを行います
- 一意の URL を生成します
- 重複しているかどうかを SQL データベースを参照して調べ、URL が一意かどうかをチェックします。
- URL が一意でない場合、別の URL を生成します。
- カスタム URL をサポートしている場合は、ユーザ提供の URL を使用できます。(同様に重複チェックもします)
- SQL Database
pastesテーブルに保存します - ペーストデータを Object Store に保存します
- URL を返します
- 一意の URL を生成します
どのくらいの量のコードを書くことになるか、インタビュアーに説明して下さい.
pastes テーブルは、以下のような構造を持ちます。
shortlink char(7) NOT NULL
expiration_length_in_minutes int NOT NULL
created_at datetime NOT NULL
paste_path varchar(255) NOT NULL
PRIMARY KEY(shortlink)
shortlink カラムに基づいた primary key を設定することで、一データベースが意性を強制するような index を作ります。 加えて、created_at に index を作成することで検索を高速化し、データをメモリに保持できます。 メモリから 1 MB を順次に読み取るのは約 250 マイクロ秒かかりますが、SSD からはその 4 倍、ディスクからはその 80 倍の時間がかかります。1
一意の URL を生成するには、以下のようにします:
- ユーザの IP アドレス + timestamp の MD5 ハッシュをとる
- MD5 は広く使用されているハッシュ関数であり、128 bit のハッシュ値を生成します
- MD5 は均一に分散されています
- 代わりに、ランダムに生成されたデータの MD5 ハッシュを取得することもできます
- Base 62 は MD5 ハッシュをエンコードします。
- Base62 は
[a-zA-Z0-9]にエンコードし、URL として上手く機能するので、特殊文字をエスケープする必要がありません。 - 元の入力値に対するハッシュ結果は1つだけであり、Base62 は確定的です (ランダム性は含まれません)
- Base64 はもう1つの一般的なエンコーディングですが、追加の
+と-文字が原因で URL に問題が生じます。 - 以下の Base 62 擬似コードは、計算量 O(k) で実行されます。k は桁数(7)です。
- Base62 は
def base_encode(num, base=62):
digits = []
while num > 0
remainder = modulo(num, base)
digits.push(remainder)
num = divide(num, base)
digits = digits.reverse
- 出力の最初の7文字をとると、62^7 通りの数が得られます。これは、3年間で3億6千万のショートリンクという制約を処理するのに十分です。
url = base_encode(md5(ip_address+timestamp))[:URL_LENGTH]
- public な REST API を使いましょう
$ curl -X POST --data '{ "expiration_length_in_minutes": "60", \
"paste_contents": "Hello World!" }' https://pastebin.com/api/v1/paste
Response:
{
"shortlink": "foobar"
}
内部通信には、Remote Procedure Calls を使用できます。
ユースケース: User は、ペーストされた URL を入力して内容を閲覧できます
- Client が、GET リクエストを Web Server に送信します
- Web Server は、リクエストを Read API サーバに転送します
- Read API サーバは以下のことをします
- 生成された URL に関して SQL Database をチェックします
- もし URL が SQL Database にあれば、Object Store からペーストコンテンツを取得します
- なければ、ユーザにエラーメッセージを返します
- 生成された URL に関して SQL Database をチェックします
REST API:
$ curl https://pastebin.com/api/v1/paste?shortlink=foobar
Response:
{
"paste_contents": "Hello World"
"created_at": "YYYY-MM-DD HH:MM:SS"
"expiration_length_in_minutes": "60"
}
ユースケース: Service は、ページの分析を追跡します
リアルタイム分析は必須ではないため, ヒットカウントを算出するために、Web Server のログを単純に MapReduce します。
どのくらいの量のコードを書くことになるか、インタビュアーに説明して下さい.
class HitCounts(MRJob):
def extract_url(self, line):
"""Extract the generated url from the log line."""
...
def extract_year_month(self, line):
"""Return the year and month portions of the timestamp."""
...
def mapper(self, _, line):
"""Parse each log line, extract and transform relevant lines.
Emit key value pairs of the form:
(2016-01, url0), 1
(2016-01, url0), 1
(2016-01, url1), 1
"""
url = self.extract_url(line)
period = self.extract_year_month(line)
yield (period, url), 1
def reducer(self, key, values):
"""Sum values for each key.
(2016-01, url0), 2
(2016-01, url1), 1
"""
yield key, sum(values)
ユースケース: Service は、期限切れのペーストを削除します
期限切れのペーストを削除するには, SQL Database をスキャンして、有効期限の timestamp が現在の timestamp より古い全てのエントリーを探します。 全ての期限切れのエントリーをテーブルから delete します(あるいは期限切れとしてマークします)。
Step 4: デザインをスケールする
制約を考慮して、ボトルネックを特定して対処します
重要: 初期設計から最終設計に直接ジャンプしないで下さい!
以下を繰り返し行うことを明言します: 1) Benchmark/Load Test, 2) ボトルネックの Profile, 3) 代替案とトレードオフを評価しながらボトルネックに対処する, 4) それらを繰り返す。 初期設計を繰り返しスケーリングする方法のサンプルとしては Design a system that scales to millions of users on AWS を見て下さい。
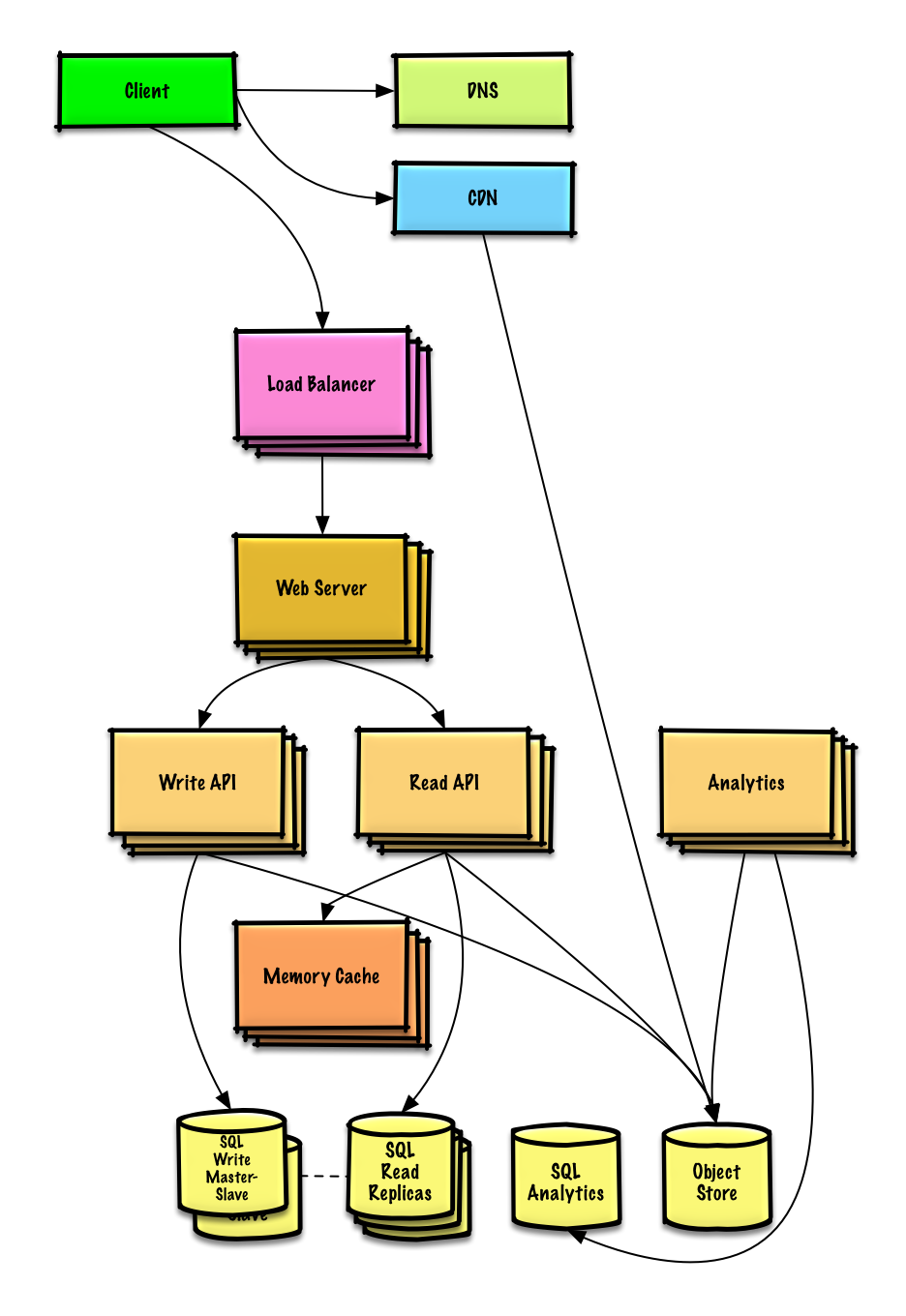
初期設計で遭遇する可能性のあるボトルネックと、それらそれぞれにどのように対処するかについて議論することが重要です。 例えば、複数の Web Servers を伴った Load Balancer を追加することで対処される問題は何ですか? CDN? Master-Slave Replicas? それぞれの代替案とトレードオフは何ですか?
設計を完了してスケーラビリティの問題に対処するために、いくつかのコンポーネントを紹介します。煩雑さを減らすために、内部ロードバランサは表示されていません。
繰り返しの議論を避けるために, 主要な話のポイント, トレードオフ, 代替案については、次のsystem design topicsを参照して下さい :
- DNS
- CDN
- Load balancer
- Horizontal scaling
- Web server (reverse proxy)
- API server (application layer)
- Cache
- Relational database management system (RDBMS)
- SQL write master-slave failover
- Master-slave replication
- Consistency patterns
- Availability patterns
Analytics Database は、Amazon Redshift や Google BigQuery のようなデータ倉庫ソリューションを使用することができます。
Amazon S3 などの Object Store は、1ヶ月あたり 12.7 GB の新しいコンテンツの制約を満足に処理できます。
1秒あたり 40 の 平均 Read リクエスト(ピーク時にはより高い)に対処するには、人気のあるコンテンツのトラフィックをデータベースではなく Memory Cache で処理する必要があります。 Memory Cache は、偏在トラフィックやトラフィックスパイクに対処するためにも有用です。 SQL Read Replicas は、レプリケーション書き込みに行き詰まっていない限りは、キャッシュミスを処理できるはずです。
1 秒あたり平均 4 回のペースト書き込み(ピーク時にはより高い)は、単一の SQL Write Master-Slave に対して実行可能でなければいけません。 そうでなければ、追加の SQL スケーリングパターンを使用する必要があります。
一部のデータを NoSQL Database に移すことも検討可能です。
追加のポイント
問題の範囲と残り時間次第で、追加の話題に踏み込みます。
NoSQL
Caching
- キャッシュする場所
- キャッシュするモノ
- キャッシュを更新するタイミング
非同期とマイクロサービス
通信
- トレードオフについて話し合う:
- クライアントとの外部通信 - HTTP APIs following REST
- 内部通信 - RPC
- Service discovery
セキュリティ
security section を参照して下さい。
レイテンシ
See Latency numbers every programmer should know.
進行中
- システムのベンチマークと監視を継続し、ボトルネックが発生した時に対処する
- スケーリングは反復的なプロセスです