120 KiB
English ∙ 日本語 ∙ 简体中文 ∙ 繁體中文 | العَرَبِيَّة ∙ বাংলা ∙ Português do Brasil ∙ Deutsch ∙ ελληνικά ∙ עברית ∙ Italiano ∙ 한국어 ∙ فارسی ∙ Polski ∙ русский язык ∙ Español ∙ ภาษาไทย ∙ Türkçe ∙ tiếng Việt ∙ Français | Add Translation
עזרו לתרגם את המדריך!
המדריך לתכנון מערכות (The System Design Primer)
מוטיבציה
ללמוד איך לתכנן מערכות ב-scale גדול.
להתכונן לראיונות ארכיטקטורה.
ללמוד איך לתכנן מערכות ב-scale גדול
ללמוד כיצד לתכנן מערכות סְקֵילָבִּילִיוּת יסייע לך להפוך למהנדס תוכנה טוב יותר.
תכנון מערכות הוא נושא רחב. יש כמות אדירה של משאבים ברחבי הרשת על עקרונות של תכנון מערכות.
ה-repo הזה הוא אוסף מסודר של משאבים שנועדו לעזור לך ללמוד איך לבנות מערכות ב-scale.
ללמוד מקהילת הקוד הפתוח
מדובר בפרויקט קוד פתוח (open source) שמתעדכן באופן מתמשך.
מוזמנים לתרום!
להתכונן לראיונות ארכיטקטורה
בנוסף לראיונות קידוד, ארכיטקטורה היא רכיב נדרש כחלק מתהליך ראיונות טכניים בהרבה חברות טכנולוגיות.
תוכל לתרגל שאלות ארכיטקטורה נפוצות ואף להשוות את התוצאות שלך עם פתרונות לדוגמה: דיונים, קוד, ודיאגרמות.
נושאים נוספים להכנה לראיונות:
כרטיסיות Anki

החבילות המוכנות של כרטיסיות Anki משתמשות בשיטת חזרתיות מבוססת מרווחים (Spaced Repetition) כדי לעזור לך לזכור מושגים חשובים בתכנון מערכות.
מומלצות לשימוש בדרכים.
משאב לראיונות קידוד: אתגרי קידוד אינטראקטיביים
מחפש משאבים שיעזרו לך להתכונן לראיונות קידוד?

תעיף מבט על ה-repo המקביל Interactive Coding Challenges, שמכיל חבילת Anki נוספת:
תרומה למדריך
ללמוד מהקהילה.
אל תהסס להגיש pull requests כדי לעזור:
- תיקון שגיאות
- שיפור קטעים קיימים
- הוספת קטעים חדשים
- תרגום לשפות נוספות
תכנים שעדיין דורשים ליטוש מסומנים בתור תחת פיתוח.
מומלץ לעיין בהנחיות לתרומה לפני התחלה.
אינדקס נושאים בארכיטקטורה
סיכומים של נושאים שונים בתכנון מערכות, כולל יתרונות וחסרונות. כל החלטה כוללת פשרות (trade-offs).
כל חלק מכיל קישורים להרחבה וללמידה מעמיקה יותר.

אינדקס נושאים
- נושאים בתכנון מערכות: התחל כאן
- ביצועים (Performance) מול סקילביליות (Scalability)
- שיהוי (Latency) מול תפוקה (Throughput)
- זמינות (Availability) מול עקביות (Consistency)
- דפוסי עקביות
- דפוסי זמינות
- מערכת שמות דומיינים (DNS)
- רשתות הפצת תוכן (CDN)
- מאזן עומסים (Load Balancer)
- פרוקסי הפוך (Reverse Proxy)
- שכבת האפליקציה
- מסדי נתונים
- מטמון (Cache)
- אסינכרוניות (asynchronism)
- תקשורת
- אבטחה
- נספחים
- תחת פיתוח
- קרדיטים
- פרטי קשר
- רישיון
מדריך למידה
נושאים מוצעים ללימוד לפי לוח הזמנים לריאיון שלך (קצר, בינוני, ארוך)

ש: עבור הראיונות, האם אני אמור לדעת כל מה שכתוב כאן?
ת: לא, אתה לא צריך לדעת הכול כדי להתכונן לריאיון.
מה שאתה תישאל עליו בריאיון תלוי בדברים כגון:
- כמה ניסיון יש לך
- מה הרקע הטכני שלך
- לאילו משרות אתה מתראיין
- באילו חברות אתה מתראיין
- מזל
לרוב מצופה ממועמדים מנוסים יותר לדעת יותר על ארכיטקטורה ותכנון מערכות. ארכיטקטים או ראשי צוותים מצופים לדעת יותר מאשר עובדים בודדים. חברות טכנולוגיות מובילות לרוב יערכו ריאיון אחד או יותר של ארכיטקטורה.
רצוי להתחיל רחב ולהעמיק במספר תחומים. זה עוזר לדעת קצת בנוגע למספר נושאי מפתח בתכנון מערכות. תתאים את המדריך לפי לוח הזמן שלך, הניסיון, המשרות שאתה מתראיין אליהן, והחברות שבהן אתה מתראיין.
- לוח זמנים קצר – התמקד ברוחב של נושאים בתכנון מערכות. תרגל פתרון של כמה שאלות ריאיון.
- לוח זמנים בינוני – התמקד ברוחב וקצת עומק של נושאים בתכנון מערכות. תרגל פתרון של הרבה שאלות ריאיון.
- לוח זמנים ארוך – התמקד ברוחב ויותר עומק של נושאים בתכנון מערכות. תרגל פתרון של רוב שאלות הריאיון.
| קצר | בינוני | ארוך | |
|---|---|---|---|
| קרא את הנושאים בתכנון מערכות כדי לקבל הבנה כללית של איך מערכות עובדות | 👍 | 👍 | 👍 |
| קרא כמה מאמרים מתוך בלוגים של חברות שאתה מתראיין אליהן | 👍 | 👍 | 👍 |
| קרא על כמה ארכיטקטורות מהעולם האמיתי | 👍 | 👍 | 👍 |
| חזור על איך לגשת לשאלת ריאיון בתכנון מערכות | 👍 | 👍 | 👍 |
| תרגל שאלות ריאיון בתכנון מערכות עם פתרונות | כמה | הרבה | רוב |
| תרגל שאלות ריאיון בתכנון מונחה עצמים עם פתרונות | כמה | הרבה | רוב |
| חזור על שאלות ריאיון נוספות בתכנון מערכות | כמה | הרבה | רוב |
איך לגשת לשאלת ריאיון ארכיטקטורה
איך לפתור שאלת ראיון ארכיטקטורה.
ראיון ארכיטקטורה הוא שיחה פתוחה. מצופה ממך להוביל אותה.
אתה יכול להיעזר בצעדים הבאים כדי להנחות את הדיון. כדי לחזק את ההבנה של התהליך, תעבור על שאלות ריאיון בתכנון מערכות עם פתרונות אל מול הצעדים הבאים:
תאר מקרי שימוש, אילוצים והנחות עבודה
אסוף דרישות והגדר את ה-scope של הבעיה. שאל שאלות כדי להבהיר את מקרי השימוש והאילוצים. דון בהנחות העבודה שאתה עושה.
- מי הולך להשתמש במערכת?
- איך הם הולכים להשתמש בה?
- כמה משתמשים יהיו?
- מה המערכת עושה?
- מה הקלטים והפלטים של המערכת?
- בכמה דאטא נצטרך לטפל?
- כמה בקשות לשניה מחכות לנו?
- מה היחס הצפוי בין קריאה לכתיבה?
שלב 2: כתוב תכנון במבט על (high level design)
כתוב תכנון high level עם כל הרכיבים החשובים.
- שרטט את הרכיבים החשובים והקשרים ביניהם
- תצדיק את הרעיונות שלך
שלב 3: תכנן את הרכיבים המרכזיים
צלול לפרטים של כל רכיב מרכזי. לדוגמה, אם התבקשת לתכנן שירות קיצור כתובות url, דון בנושאים הבאים:
- יצירה ואחסון hash של ה-url המלא
- המרה של כתובת מקוצרת לכתובת המלאה
- חיפוש ב-DB
- תכנון API ותכנון מונחה עצמים
שלב 4: תבצע scale לתכנון
זהה וטפל בצווארי בקבוק, בהתאם לאילוצים. למשל, האם תזדקק לאחד מהפתרונות הבאים כדי להתמודד עם בעיות של סקילביליות?
- מאזן עומסים (Load balancer)
- סקיילינג אופקי (Horizontal scaling)
- שמירה במטמון (Caching)
- פיצול בסיס נתונים (Database sharding)
דון בפתרונות אפשריים וה-trade-offs. הכול הוא trade-off. התמודד עם צווארי בקבוק בעזרת עקרונות תכנון מערכת סקילבילית.
חישובים "על גב המעטפה" (מהירים)
ייתכן שיבקשו ממך לבצע הערכות באופן ידני. ראה את הנספח עבור המשאבים הבאים:
- Use back of the envelope calculations
- Powers of two table
- Latency numbers every programmer should know
מקורות לקריאה נוספת
עיין בקישורים הבאים כדי להבין טוב יותר למה לצפות:
שאלות ריאיון תכנון מערכות עם פתרונות
שאלות נפוצות בריאיון ארכיטקטורה עם הסברים לדוגמה, קוד, ודיאגרמות.
הפתרונות מפנים לתוכן שנמצא בתיקיית
solutions/.
| שאלה | פתרון |
|---|---|
| תכנן את pastebin.com (או bit.ly) | פתרון |
| תכנן את ציר הזמן והחיפוש של טוויטר (או הפיד והחיפוש של פייסבוק) | פתרון |
| תכנן web crawler | פתרון |
| תכנן את Mint.com | פתרון |
| תכנן את מבני הנתונים של רשת חברתית | פתרון |
| תכנן אחסון key-value למנוע חיפוש | פתרון |
| תכנן את מנגנון דירוג המכירות לפי קטגוריה של אמזון | פתרון |
| תכנן מערכת שיכולה לגדול למיליוני משתמשים על AWS | פתרון |
| הוסף שאלה לתכנון מערכת | תרום |
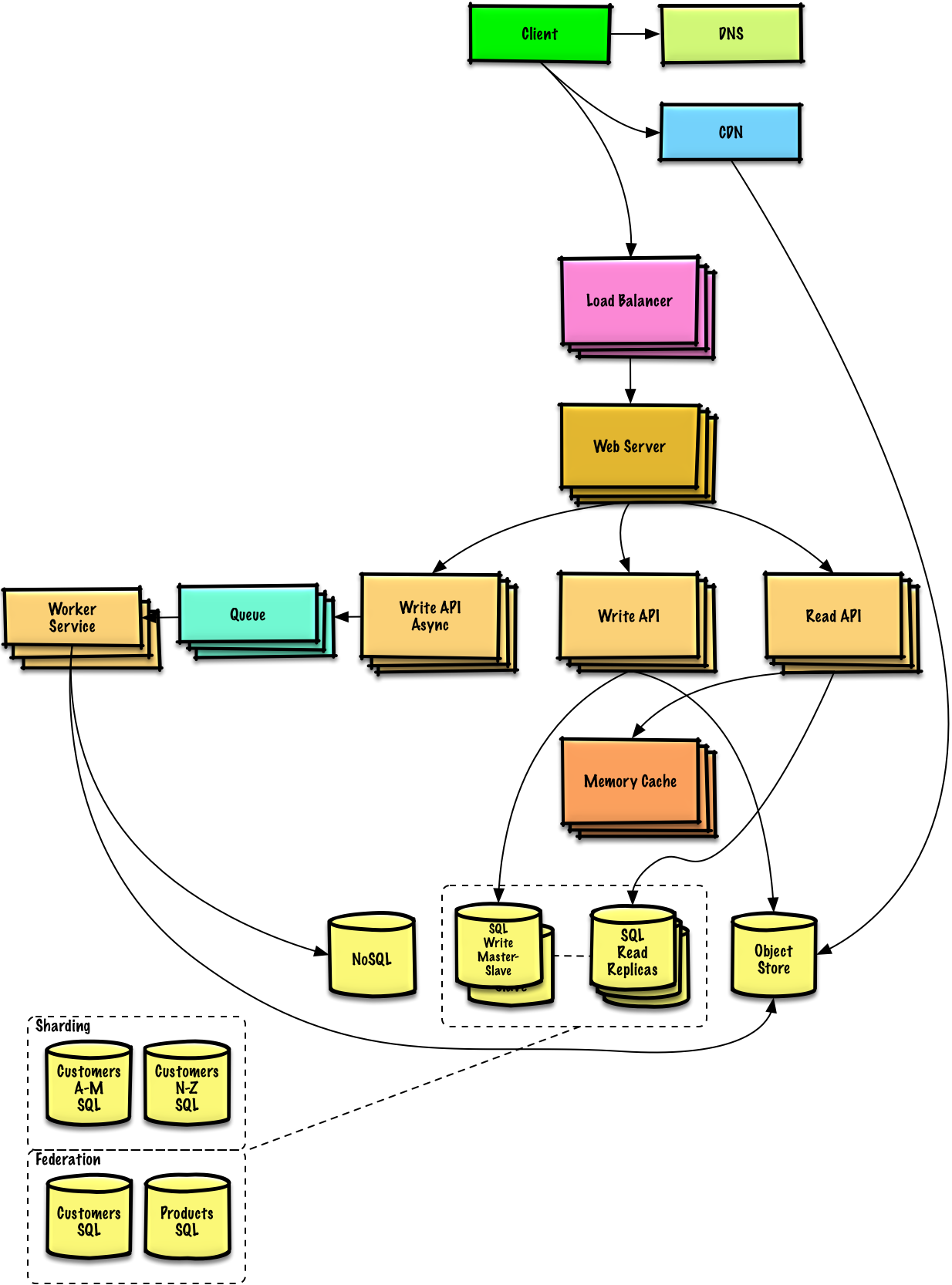
תכנן את pastebin.com (או bit.ly)
הצג/הסתר דיאגרמה

תכנן את ציר הזמן והחיפוש של טוויטר (או הפיד והחיפוש של פייסבוק)
הצג/הסתר דיאגרמה
תכנן web crawler
הצג/הסתר דיאגרמה
תכנן את Mint.com
הצג/הסתר דיאגרמה

תכנן את מבני הנתונים של רשת חברתית
הצג/הסתר דיאגרמה

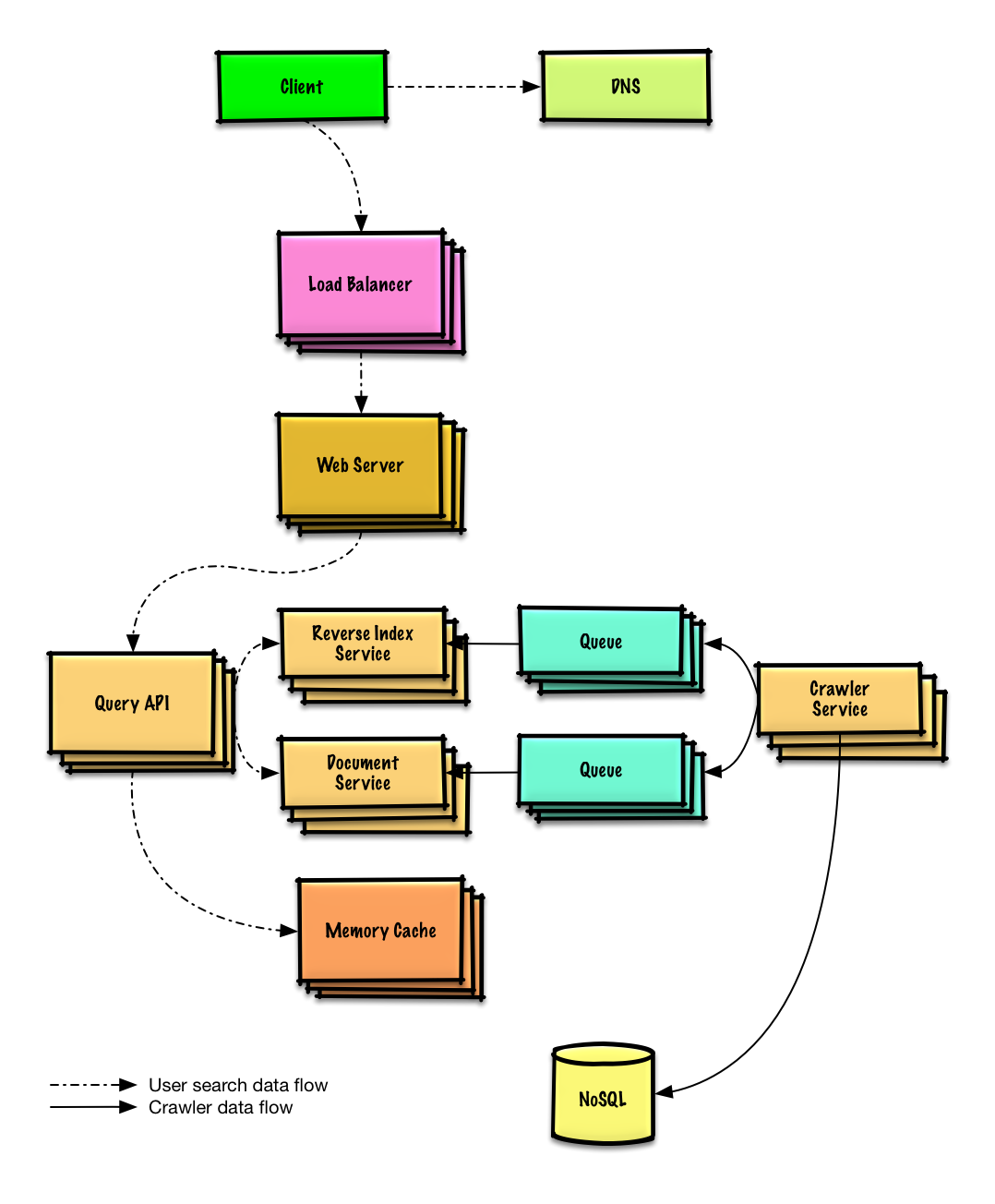
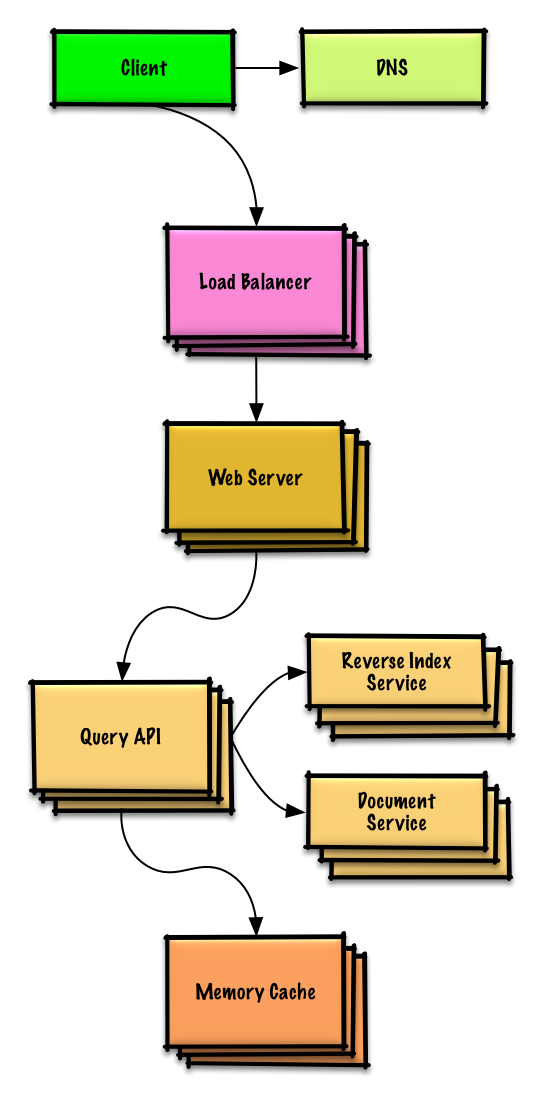
תכנן אחסון key-value למנוע חיפוש
הצג/הסתר דיאגרמה
תכנן את מנגנון דירוג המכירות לפי קטגוריה של אמזון
הצג/הסתר דיאגרמה

תכנן מערכת שיכולה לגדול למיליוני משתמשים על AWS
הצג/הסתר דיאגרמה
שאלות ריאיון בתכנון מונחה עצמים עם פתרונות
שאלות נפוצות בתכנון מונחה עצמים עם הסברים לדוגמה, קוד, ודיאגרמות.
הפתרונות מפנים לתוכן שנמצא בתיקיית
solutions/.
הערה: החלק הזה עדיין בפיתוח
| שאלה | פתרון |
|---|---|
| תכנן Hash Map | פתרון |
| תכנן מנגנון Cache בשיטת Least Recently Used | פתרון |
| תכנן מרכז שירות טלפוני (Call Center) | פתרון |
| תכנן חפיסת קלפים | פתרון |
| תכנן חניון | פתרון |
| תכנן שרת צ'אט | פתרון |
| תכנן מערך מעגלי | תרום |
| הוסף שאלה בעיצוב מונחה עצמים | תרום |
נושאים בתכנון מערכות: התחל כאן
חדש בתחום תכנון מערכות?
ראשית, תצטרך לקבל הבנה בסיסית של העקרונות הנפוצים, ללמוד מה הם, איך משתמשים בהם, מה היתרונות והחסרונות של כל אחד מהם.
שלב 1: צפה בהרצאה על סקילביליות
Scalability Lecture at Harvard
- Topics covered:
- Vertical scaling
- Horizontal scaling
- Caching
- Load balancing
- Database replication
- Database partitioning
שלב 2: קרא מאמר על סקילביליות
- Topics covered:
השלבים הבאים
בהמשך, נסתכל על trade-offs ב-high level:
- Performance vs scalability
- Latency vs throughput
- Availability vs consistency
נזכור כי הכול זה trade-off. לאחר מכן נצלול לנושאים ספציפיים יותר כמו DNS, CDN ו-load balancers.
ביצועים (Performance) מול סקילביליות (Scalability)
שירות הוא סקילבילי (scalable) אם הוא משתפר בביצועים (performance) שלו באופן פרופורציונלי למשאבים שנוספו. באופן כללי, שיפור בביצועים פירושו היכולת לתת שירות ליותר יחידות עבודה, אך הוא יכול גם לבוא לידי ביטוי ביכולת להתמודד עם יחידות עבודה גדולות יותר, ככל שהדאטא גדל.1
דרך נוספת להסתכל על ביצועים מול סקילביליות
- אם יש לך בעיית ביצועים, המערכת איטית עבור משתמש בודד.
- אם יש לך בעיית סקילביליות, המערכת מהירה עבור משתמש בודד אך איטית בעומס כבד.
מקורות וקריאה נוספת
שיהוי (Latency) מול תפוקה (Throughput)
שיהוי הוא הזמן שנדרש כדי לבצע פעולה כלשהי או להפיק תוצאה כלשהי
תפוקה היא מספר הפעולות או התוצאות ליחידת זמן.
באופן כללי, כדאי לשאוף לתפוקה מקסימלית עם שיהוי סביר.
חומרים וקריאה נוספת
זמינות (Availability) מול עקביות (Consistency)
משפט CAP
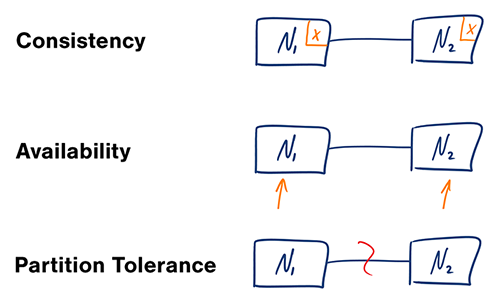
במערכות מחשוב מבוזרות, ניתן לתמוך רק בשניים מתוך שלושת התנאים הבאים:
- עקביות (Consistency) – כל קריאה מקבלת את הכתיבה העדכנית ביותר, או שגיאה.
- זמינות (Availability) - כל בקשה תקבל מענה, ללא הבטחה שהמידע שיחזור יהיה העדכני ביותר.
- עמידות לפיצול (Partition Tolerance) - המערכת ממשיכה לתפקד גם במקרים בהם נאבדות או מתעכבות מספר הודעות בין שרתי המערכת בגלל בעיות תקשורת.
ניתן לצאת מנקודת הנחה שרשתות לא אמינות - כך שנהיה חייבים לתמוך ב-״Partition tolerance״. לכן, נצטרך לבחור אחד משני האחרים - זמינות או עקביות.
בחירה ב-CP - עקביות ועמידות לפיצול
המתנה לתשובה מהמערכת (אשר סובלת מ-network partition) עלולה להסתיים בשגיאת timeout. לכן, CP הוא בחירה טובה במידה ויש הצדקה עסקית לקריאות וכתיבות אטומיות.
בחירה ב-AP - זמינות ועמידות לפיצול
תשובות לבקשות מהמערכת מחזירות את הגרסה הזמינה ביותר של הנתונים הזמינים בשרת הרלוונטי, שאינה בהכרח האחרונה. כתיבה עשויה לקחת זמן מסוים עד שתסתיים, עד אשר התקשורת הבעייתית תיפתר.
לכן, AP הוא בחירה טובה במידה ויש הצדקה עסקית לעבוד במצב של eventual consistency או במידה והמערכת צריכה להמשיך לשרת למרות שגיאות בלתי-תלויות.
חומרים וקריאה נוספת
דפוסי עקביות (Consistency Patterns)
כאשר קיימים מספר עותקים של אותם נתונים, עלינו להחליט כיצד לסנכרן ביניהם כדי שלקוחות יקבלו תצוגה עקבית של המידע.
ניזכר בהגדרה של עקביות מתוך משפט CAP: כל קריאה מקבלת את הכתיבה העדכנית ביותר או שגיאה.
עקביות חלשה (Weak Consistency)
לאחר כתיבה, קריאות עשויות לראות או לא לראות את הערך החדש שנכתב. הגישה כאן היא של best effort - המאמץ הטוב ביותר.
גישה זו נפוצה במערכות כמו memcached. עקביות חלשה מתאימה למקרים של מערכות זמן-אמת, כמו VoIP, שיחות וידאו, ומשחקים מרובי משתתפים.
לדוגמה, אם אתה בשיחת טלפון ומאבד קליטה לכמה שניות, כשאתה חוזר אתה לא שומע מה שנאמר בזמן שלא הייתה קליטה.
עקביות לא מיידית (Eventual Consistency)
לאחר כתיבה, הקריאות יראו בסופו של דבר את מה שנכתב (בדרך כלל תוך מספר מילישניות). הנתונים משוכפלים באופן אסינכרוני.
גישה זו נפוצה במערכות כמו DNS ומייל. עקביות לא מיידית מתאימה למערכות ששומרות על זמינות גבוהה במיוחד.
עקביות חזקה (Strong Consistency)
לאחר כתיבה, הקריאות יראו תמיד את הערך החדש שנכתב. השכפול מתבצע באופן סינכרוני.
גישה זו נפוצה במערכות קבצים ובמסדי נתונים רלציוניים (RDBMS). עקביות חזקה מתאימה למערכות שדורשות טרנזקציות.
מקורות וקריאה נוספת
דפוסי זמינות (Availability Patterns)
קיימים שני דפוסים משלימים לתמיכה בזמינות גבוהה: מעבר אוטומטי (fail-over) ו-שכפול (replication).
גיבוי בזמן כישלון (Fail-Over)
אקטיבי-פסיבי (Active-Passive)
במבנה אקטיבי-פסיבי, נשלחים heartbeat-ים בין השרת הפעיל לשרת הרזרבי (הפסיבי). אם ה-heartbeat נקטע, השרת הפסיבי לוקח את כתובת ה-IP של הפעיל וממשיך את השירות.
משך זמן ההשבתה תלוי אם השרת הפסיבי פועל מראש במצב 'חם' (hot standby), או שיש להפעילו ממצב 'קר' (cold standby). רק השרת הפעיל מקבל תעבורה.
סוג זה נקרא גם Master-Slave.
אקטיבי-אקטיבי (Active-Active)
במבנה אקטיבי-אקטיבי, שני השרתים מקבלים תעבורה ומחלקים ביניהם את העומס.
אם השרתים חשופים פומבית, שרת ה-DNS צריך לדעת על כתובות ה-IP הציבוריות של שניהם. אם השרתים פנימיים, על לוגיקת האפליקציה להכיר את שניהם.
סוג זה נקרא גם Master-Master.
חסרונות של מעבר אוטומטי
- מעבר אוטומטי מוסיף חומרה ועלות תפעולית.
- קיימת אפשרות לאובדן נתונים אם המערכת הפעילה קורסת לפני שהספיקה לשכפל את המידע למערכת הפסיבית.
שכפול (Replication)
עבור Master-Slave/Master-Master
נושא זה נדון בפירוט נוסף בחלק על מסדי נתונים:
זמינות במספרים
נהוג למדוד זמינות לפי זמן פעילות (uptime) או חוסר פעילות (downtime)כאחוז מהזמן שבו השירות פועל. המדד הנפוץ הוא לפי מספר התשיעיות — לדוגמה: שירות עם זמינות של 99.99% מתואר כבעל ארבע תשיעיות.
זמינות של 99.9% — שלוש תשיעיות
| Duration | Acceptable downtime |
|---|---|
| Downtime per year | 8h 45min 57s |
| Downtime per month | 43m 49.7s |
| Downtime per week | 10m 4.8s |
| Downtime per day | 1m 26.4s |
זמינות של 99.99% — ארבע תשיעיות
| Duration | Acceptable downtime |
|---|---|
| Downtime per year | 52min 35.7s |
| Downtime per month | 4m 23s |
| Downtime per week | 1m 5s |
| Downtime per day | 8.6s |
זמינות במקביל לעומת בטור
אם שירות מורכב ממספר רכיבים שעלולים להיכשל, הזמינות הכוללת של השירות תלויה באופן שבו הם מסודרים - בטור או במקביל.
בטור
כאשר שני רכיבים עם זמינות קטנה מ-100% מסודרים בטור, הזמינות הכוללת יורדת:
Availability (Total) = Availability (Foo) * Availability (Bar)
אם גם Foo וגם Bar זמינים ברמה של 99.9%, הזמינות הכוללת שלהם בטור תהיה 99.8%.
במקביל
הזמינות הכוללת עולה כאשר שני רכיבים בעלי זמינות קטנה מ־100% פועלים במקביל:
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))
אם גם Foo וגם Bar זמינים ברמה של 99.9%, הזמינות הכוללת שלהם במקביל תהיה 99.9999%.
מערכת שמות דומיינים (DNS)

מערכת שמות דומיינים (DNS) ממירה שם דומיין כמו www.example.com לכתובת IP.
ה-DNS בנוי בהיררכיה: כאשר ישנם כמה שרתי ניהול בשכבה העליונה. ה-router שלך או ספק האינטרנט (ISP) מספקים כתובות לשרת(י) DNS שיש לפנות אליהם בעת ביצוע חיפוש של כתובת.
שרתי DNS בשכבה נמוכה יותר, מבצעים cache למיפויים, שעלולים להיות לא עדכניים (stale) אם הרשומה המעודכנת עוד לא עברה מהשרת בשכבה הגבוהה עד למטה (propagation delays).
המיפוי של ה-DNS יכול להישמר על ידי הדפדפן או מערכת ההפעלה לפרק זמן מסוים, הנקבע על ידי TTL – Time To Live.
- NS record (Name Server) – מגדירה את שרתי DNS עבור הדומיין/תת-דומיין.
- MX record (Mail Exchange) – מגדירה את שרתי הדואר לקבלת הודעות.
- A record (Address) – ממפה שם לכתובת IP.
- CNAME (Canonical Name) – ממפה שם לשם אחר (למשל example.com →
www.example.com) או לרשומתA.
שירותים מנוהלים כמו CloudFlare ו-Route 53 מספקים DNS מנוהל.
חלקם מאפשרים ניתוב תעבורה בשיטות שונות:
- Weighted round robin
- Prevent traffic from going to servers under maintenance
- Balance between varying cluster sizes
- A/B testing
- Latency-based
- Geolocation-based
חסרונות (DNS)
- פנייה לשרת DNS מוסיפה עיכוב קל, אם כי ברוב המקרים הוא מתמתן בזכות caching כפי שתואר קודם.
- ניהול שרתי DNS יכול להיות מורכב, ולרוב מנוהל על-ידי ממשלות, ISPs וחברות גדולות.
- שירותי DNS היו יעד לאחרונה ל-מתקפות DDoS, מה שמנע מגולשים להגיע לאתרים (למשל Twitter) בלי להכיר כתובות IP ידניות.
מקורות וקריאה נוספת
רשתות הפצת תוכן (CDN)

רשת הפצת תוכן (CDN) היא רשת גלובלית ומבוזרת של שרתי proxy, אשר מנגישים תכנים ממיקומים הקרובים יותר למשתמש הקצה. בדרך כלל, קבצים סטטיים כמו HTML/CSS/JS, תמונות וסרטונים, מונגשים על ידי CDN, למרות שיש כאלו כמו CloudFront של Amazon התומכים גם בתכנים דינמיים. מיפוי ה-DNS שיתקבל ינחה את הלקוחות לאיזה שרת להתחבר.
הגשת תוכן מ-CDN משפר ביצועים משמעותית בשני אופנים:
- המשתמש מקבל תוכן מ-data center הקרוב אליו פיזית.
- השרתים אינם צריכים לשרת בקשות שה-CDN מספק במקומם.
דחיפה (Push)
ב-Push CDN התוכן נדחף אל ה-CDN בכל פעם שהוא משתנה בשרת המקור. האחריות על העלאת הקבצים וכתיבת ה-URLs המופנים ל-CDN היא שלך. אתה מגדיר את הזמן שבו פג תוקפו של תוכן מסוים, ומתי הוא מתעדכן.
תוכן מועלה רק כאשר הוא חדש, או עבר שינוי, מה שמפחית תעבורה אבל ממקסם על האחסון. אתרים עם מעט תוכן או תעבורה, או עם תוכן שלא מתעדכן באופן תדיר עובדים טוב עם Push CDN. התוכן נמצא ב-CDN פעם אחת, במקום שישלפו אותו מחדש בתדירות קבועה.
משיכה (Pull)
ב-Pull CDN התוכן נשלף מהשרת המקור רק כאשר משתמש מבקש אותו לראשונה. הקבצים נשארים בשרת שלך ו-URLs מפנים ל-CDN. הבקשה הראשונית איטית יותר עד שהקובץ נשמר ב-CDN. משך הזמן שבו ישאר ה-cache נקבע על-ידי TTL – Time to Live.
ה-Pull CDN חוסך שטח אחסון על ה-CDN, אך עלול ליצור תעבורה מיותרת אם קבצים פגי-תוקף נשלפים שוב לפני ששונו בפועל. Pull CDN מתאים לאתרים עתירי תעבורה, שכן העומס מתפזר וה-CDN שומר רק קבצים שנדרשו לאחרונה.
חסרונות (CDN)
- עלויות CDN עשויות להיות משמעותיות בהתאם לנפח התעבורה, אך יש לשקול אותן מול העלויות שהיית משלם ללא CDN.
- תוכן עלול להיות מיושן (stale) אם עודכן לפני שפג תוקף ה-TTL.
- יש צורך לשנות את כתובות ה-URL של תוכן סטטי כך שיפנו אל ה-CDN.
מקורות וקריאה נוספת
מאזן עומסים (Load Balancer)
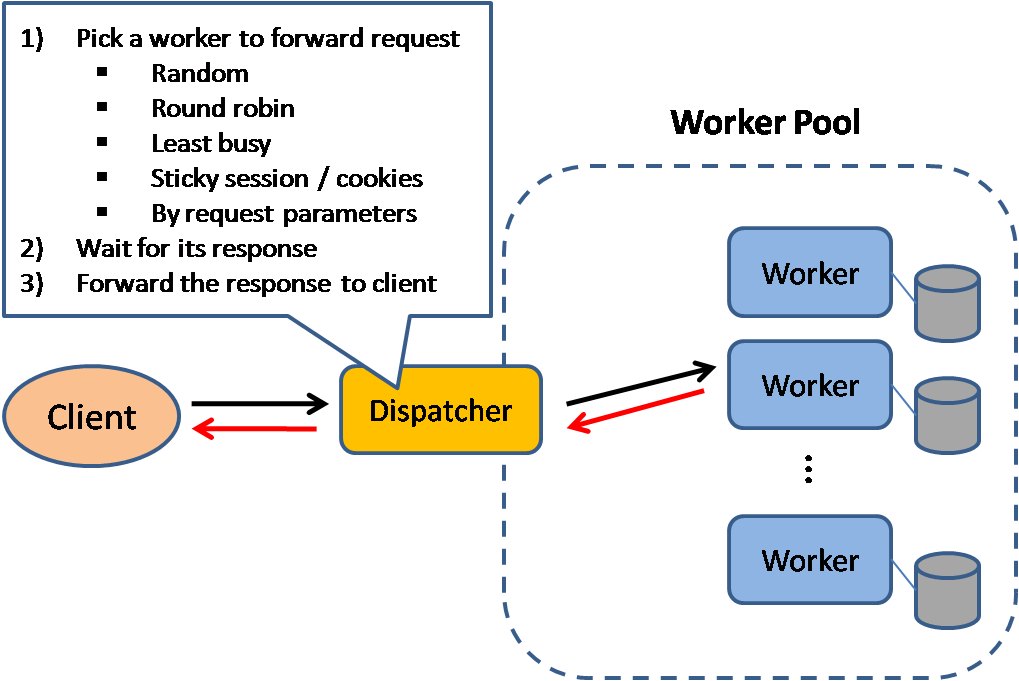
Source: Scalable system design patterns
מאזן עומסים מבזר בקשות נכנסות מלקוח בין משאבי חישוב שונים כגון שרתי אפליקציה ומסדי נתונים. עבור כל בקשה, הוא מחזיר את התשובה ממשאב החישוב המתאים, אל הלקוח המתאים. מאזן עומסים יעיל ב:
- מניעת שליחת בקשות לשרתים לא יציבים (unhealthy)
- מניעת העמסת־יתר על משאבים
- סילוק נקודת כשל בודדת (SPOF)
מאזן עומסים ניתן למימוש כחומרה (יקר) או כתוכנה כדוגמת HAProxy.
יתרונות נוספים:
- SSL Termination – טכניקת אבטחה שבה מפענחים בקשות נכנסות לפני שהן מגיעות לשרת הקצה, ומצפינים את התשובות של השרת כך ששרתי ה-backend לא צריכים לבצע את הפעולות היקרות הללו.
- מוריד את הצורך להתקין תעודות X.509 על כל שרת.
- Session Persistence – יצירת עוגיות (cookies) וניתוב בקשות של לקוח מסוים לאותו מופע שהתנהל מולו, אם האפליקציה לא מנהלת סשנים בעצמה.
כדי להגן מפני כישלונות נהוג להקים מספר מאזני עומסים, במצב
Active-Passive או Active-Active.
מאזן עומסים יכול לנתב את התעבורה על פי מדדים שונים:
- Random
- Least loaded
- Session/cookies
- Round robin or weighted round robin
- Layer 4
- Layer 7
איזון עומסים בשכבה 4
מאזני עומסים בשכבה 4 בוחנים מידע בשכבת התעבורה (transport layer) כדי להחליט כיצד להפיץ בקשות.
בדרך כלל, מדובר בכתובות ה-IP של המקור והיעד ובפורטים שבכותרת (header), ולא בתוכן הפקטה (packet).
מאזני עומסים בשכבה 4 מעבירים את חבילות הרשת אל ומן השרת הנבחר (upstream server) תוך ביצוע
תרגום כתובות רשת (NAT).
איזון עומסים בשכבה 7
מאזני עומסים בשכבה 7 בוחנים את שכבת האפליקציה כדי להחליט כיצד להפיץ בקשות. ההחלטה יכולה להתבסס על תוכן הכותרות (headers), גוף ההודעה, ועוגיות (cookies).
מאזן עומסים בשכבה 7 מסיים (terminates) את תעבורת הרשת אל מול הלקוח, קורא את ההודעה, מקבל החלטת איזון-עומסים, ואז פותח חיבור לשרת שנבחר.
למשל, מאזן כזה יכול לשלוח תעבורת וידאו לשרתים שמאחסנים קטעי וידאו, ובמקביל לנתב תעבורת חיוב משתמשים (billing) לשרתים מוקשחים אבטחתית.
לעומת זאת, איזון עומסים בשכבה 4 דורש פחות זמן ומשאבי מחשוב מאשר שכבה 7, אם כי על חומרה מודרנית ההשפעה הביצועית עשויה להיות מזערית.
גדילה אופקית (Horizontal Scaling)
מאזני עומסים מסייעים גם בגדילה אופקית (Horizontal Scaling), וכך משפרים ביצועים וזמינות.
הרחבת המערכת באמצעות שרתים זולים חסכונית יותר ומביאה לרמת זמינות גבוהה לעומת הגדלה אנכית (Vertical Scaling) – חיזוק שרת יחיד בחומרה יקרה. בנוסף, קל יותר לגייס אנשי מקצוע המיומנים בעבודה עם שרתים סטנדרטיים מאשר כאלה המתמחים במערכות ארגוניות ייעודיות ויקרות.
חסרונות: גדילה אופקית
- גדילה אופקית מוסיפה מורכבות וכוללת שכפול שרתים
- השרתים צריכים להיות stateless: אין לאחסן בהם מידע משתמש כגון סשנים או תמונות פרופיל
- ניתן לשמור סשנים באחסון נתונים מרכזי כגון מסד־נתונים (SQL או NoSQL) או מטמון פרסיסטנטי (Redis, Memcached)
- שרתים בהמשך השרשרת (downstream) למשל cache ו-DB צריכים להתמודד עם יותר חיבורים בו-זמנית ככל שמספר שרתי האפליקציה גדל
חסרונות: מאזן עומסים
- מאזן העומסים עצמו עלול להפוך לצוואר בקבוק בביצועים אם אין לו מספיק משאבים או אם הוא מוגדר בצורה לא נכונה.
- הוספת מאזן עומסים כדי להסיר נקודת כשל בודדת (SPOF) מוסיפה מורכבות למערכת.
- מאזן עומסים יחיד הוא SPOF, ועבודה עם מספר מאזני עומסים מגדילה עוד יותר את המורכבות.
מקורות וקריאה נוספת
פרוקסי הפוך (Reverse Proxy)
פרוקסי הפוך הוא שרת אינטרנט המרכז שירותים פנימיים ומספק ממשק אחיד החוצה. בקשות שמגיעות מלקוחות מועברות לשרת ה-backend המסוגל לטפל בהן, ולאחר מכן הפרוקסי מחזיר ללקוח את תגובת השרת.
יתרונות הכלולים בצורה זו:
- אבטחה מוגברת – הסתרת מידע על שרתי ה-backend, חסימת כתובות IP, הגבלת מספר חיבורים לכל לקוח
- גמישות וסקילביליות מוגברת – הלקוחות רואים רק את כתובת ה-IP של הפרוקסי, מה שמאפשר להגדיל/לשנות שרתים בלי להשפיע על הלקוחות
- SSL Termination – טכניקת אבטחה שבה מפענחים בקשות נכנסות לפני שהן מגיעות לשרת הקצה, ומצפינים את התשובות של השרת כך ששרתי ה-backend לא צריכים לבצע את הפעולות היקרות הללו.
- מוריד את הצורך להתקין תעודות X.509 על כל שרת.
- דחיסה – דחיסת תגובות השרת
- מטמון – החזרת תגובות עבור בקשות שמורות (cached)
- תוכן סטטי – הנגשת קבצים סטטיים ישירות
- קבצי HTML/CSS/JS
- תמונות
- סרטונים
מאזן עומסים לעומת פרוקסי הפוך
- פריסת מאזן עומסים שימושית כשקיימים מספר שרתים. לרוב הוא מנתב תעבורה לקבוצת שרתים המבצעים אותה לוגיקה.
- פרוקסי הפוך מועיל גם כאשר יש רק שרת אינטרנט/אפליקציה אחד – ומעניק את כל היתרונות שפורטו לעיל.
- פתרונות כמו NGINX ו-HAProxy תומכים גם בפרוקסי הפוך בשכבה 7 וגם באיזון עומסים.
חסרונות: פרוקסי הפוך
- הכנסת פרוקסי הפוך מוסיפה מורכבות לארכיטקטורה.
- פרוקסי הפוך יחיד הוא SPOF. הגדרת כמה כאלו להפחתת סיכון (Fail-over) מוסיפה מורכבות נוספת.
מקורות וקריאה נוספת
שכבת האפליקציה
הפרדת שכבת הרשת משכבת האפליקציה (ידועה גם כשכבת ה-platform), מאפשרת לבצע scaling ולקנפג את שתי השכבות באופן בלתי תלוי. הוספת API חדש גוררת הוספתי שרתי אפליקציה, מבלי להוסיף בהכרח גם שרתי המטפלים בלוגיקת הרשת.
עקרון האחריות היחידה (single respoinsibility principle) מעודד סרביסים עצמאיים וקטנים שעובדים יחד. צוותים קטנים המטפלים שירותים קטנים יכלוים להתכוונן בצורה מיטבית לגדילה מהירה. Workers בשכבת האפליקציה מסייעים גם לא-סינכרוניות.
מיקרו-סרביסים (Microservices)
במונח Microservices הכוונה למערך של שירותים קטנים, מודולריים, הניתנים לפריסה עצמאית. כל שירות רץ כתהליך נפרד ומתקשר באמצעות מנגנון פשוט ומוגדר היטב כדי להשיג יעד עסקי.1
לדוגמה, ב-Pinterest יכולים להיות המיקרו-סרביסים הבאים: פרופיל משתמש, עוקבים, פיד, חיפוש, העלאת תמונה וכו'.
גילוי סרביסים (Service Discovery)
מערכות כמו Consul, Etcd, ו-Zookeeper מסייעות לשירותים “למצוא” זה את זה על ידי ניהול ומעקב אחר שמות הסרביסים, כתובות IP, ופורטים. בדיקות דופק (Health checks) — מאמתות את תקינות השירות, לעיתים קרובות באמצעות endpoint HTTP. גם Consul וגם Etcd כוללים אחסון key-value מובנה, השימושי לאחסון קונפיגורציה ונתונים משותפים.
חסרונות: שכבת האפליקציה
- הוספת שכבת אפליקציה עם סרביסים שהקשר ביניהם רופף (loosely coupled) דורשת גישה שונה בארכיטקטורה, תפעול ותהליכי פיתוח (לעומת מערכת מונוליטית).
- מיקרו-סרביסים עלולים להוסיף מורכבות מבחינת פריסות ותפעול.
מקורות וקריאה נוספת
מסדי נתונים (DB)

Source: Scaling up to your first 10 million users
מסדי נתונים רלציוניים (RDBMS)
מסד נתונים רלציוני כמו SQL הוא אוסף פריטי מידע המאורגנים בטבלאות. ACID הוא סט מאפיינים של טרנזקציות במסדי נתונים רלציוניים:
- Atomicity – כל טרנזקציה מתבצעת בשלמותה או שלא מתבצעת כלל (all or nothing).
- Consistency – טרנזקציה מעבירה את ה-DB ממצב תקין אחד למצב תקין אחר.
- Isolation – הרצה במקביל של טרנזקציות שקולה להרצה סדרתית שלהן.
- Durability – לאחר שטרנזקציה הסתיימה, היא תישאר קבועה גם בקריסת מערכת.
ישנן טכניקות רבות להגדלת (scaling) מסד נתונים רלציוני:
שכפול Master-Slave, שכפול Master-Master, פדרציה (Federation), חלוקה (Sharding), דה-נורמליזציה (Denormalization), ו-SQL Tuning.
שכפול Master-Slave
ה-master משרת קריאות וכתיבות (RW), ומשכפל את הכתיבות ל-slave אחד או יותר שמשרת רק קריאות (R). ה-slaves יכול לשכפל את הדאטא ל-slaves נוספים במבנה של מעין עץ. אם ה-master נופל, המערכת יכולה להמשיך לרוץ במצב read-only עד שאחד ה-slaves מקודם להיות master, או שמקצים master חדש.

Source: Scalability, availability, stability, patterns
חסרונות: Master-Slave
- נדרשת לוגיקה לקידום slave ל-master.
- ראה חסרונות: replication – רלוונטי גם ל-Master-Slave וגם ל-Master-Master.
שכפול Master-Master
שני ה-masters משרתים קריאה וכתיבה (RW) ומתאמים אחד עם השני את הכתיבות. אם אחד מהם נופל, המערכת יכולה להמשיך לתפקד במצב של קריאה וכתיבה.

Source: Scalability, availability, stability, patterns
חסרונות: Master-Master
- נדרש מאזן עומסים או שינוי לוגיקת האפליקציה כדי להחליט לאן לכתוב.
- רוב מערכות ה-Master-Master מפרות עקרון של עקביות (לכן מפרות ACID) או סובלות מאיטיות כתיבה עקב הצורך לבצע סנכרון.
- ככל שמתרבים שרתים שמאפשרים כתיבה וה-latency גדל, יש צורך להכריע יותר מקרים של conflict.
- ראה חסרונות: replication.
חסרונות: Replication (כללי)
- סכנת אובדן נתונים אם ה-master נופל לפני ששוכפל מידע חדש שנכתב.
- כל שינוי ב-master משתכפל לרפליקות, מה שגורם להן להיות עסוקות בשחזור הכתיבות, וזה מאט את הקריאות מהן.
- כל רפליקה נוספת מובילה ל-lag גדול יותר בקריאה עקב הצורך לשכפל את כל המידע לכל הרפליקות.
- בחלק מהמערכות, כתיבה ל-master יכולה להיות multi-threaded בעוד שברפליקות לרוב הכתיבה היא סנכרונית עם thread בודד.
- שכפול מוסיף עוד חומרה ומורכבות.
מקורות וקריאה נוספת: Replication
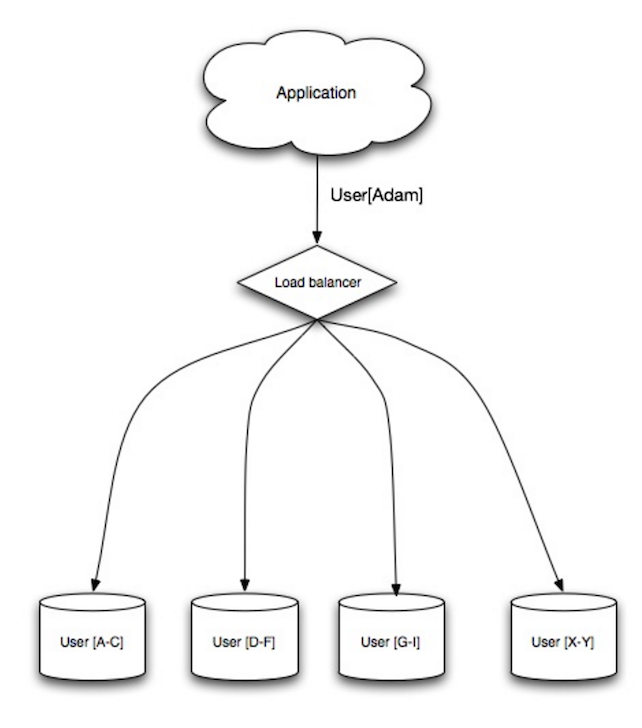
פדרציה (Federation)

Source: Scaling up to your first 10 million users
בפדרציה (או חלוקה פונקציונלית) מפצלת DB לפי הפונקציות שלו. לדוגמה, במקום DB מונוליטי בודד, ניתן לנהל 3 DBים נפרדים: פורומים, משתמשים, ומוצרים, מה שגורר פחות תעבורת קריאה וכתיבה לכל DB, ועקב כך פחות replication lag. מסדי נתונים קטנים יותר מאפשרים יותר דאטא שנכנס בזיכרון, שיכול להוביל ליותר cache hits מוצלחים. בלי master אחד מרכזי שאחראי לדאוג לכל הכתיבות באופן סדרתי, אפשר לכתוב במקביל ל-DB שונים עבור כל סוג של נתונים, ובכך להגדיל את ה-throughput.
חסרונות: פדרציה
- לא יעיל אם הסכימה דורשת טבלאות עצומות.
- הלוגיקה באפליקציה צריכה להתעדכן כדי לדעת לאיזה DB לפנות.
- ביצוע פעולת JOIN משני DBים קשה יותר ודורש server link.
- דורשת הוספה של עוד חומרה ומורכבות.
מקורות וקריאה נוספת: פדרציה
חלוקה (Sharding)
Source: Scalability, availability, stability, patterns
חלוקה מפזרת את הדאטא בין DBים שונים כך שכל DB מנהל חלק (subset) מסוים של הדאטא. נסתכל למשל על DB של משתמשים, ככל שכמות המשתמשים עולה, יותר חלקים (shards) מתווספים ל-cluster.
בדומה ליתרונות של פדרציה, חלוקה גוררת פחות תעבורה של קריאות וכתיבות, פחות שכפול, ויותר cache hits. גודל ה-index גם קטן, מה שלרוב משפר את קצב ביצוע השאילתות. אם shard אחד נופל, כל שאר ה-shards עדיין פעילים, למרות שנרצה לבצע שכפול מסוים כדי להימנע מאיבוד מידע. כמו פדרציה, אין master מרכזי אחיד שכל הכתיבות עוברות דרכו, מה שמאפשר לכתוב במקביל ל-DBים שונים ולהגביר את ה-throughput.
דרכים נפוצות לבצע sharding לטבלה של משתמשים הן באמצעות האות הראשונה של שם המשפחה, או המיקום הגיאוגרפי של המשתמש.
חסרונות: Sharding
- הקוד צריך לדעת באיזה shard הנתונים נמצאים, דבר הגורר שאילתות SQL מורכבות.
- התפלגות נתונים עלולה להיות לא אחידה, קבוצה של power users על אותו ה-shard יכולה להביא לעומס מוגבר לאותו ה-shard ביחס לאחרים. ביצוע rebalance גורר מורכבות נוספת. פונקציית sharding המבוססת על Consistent Hashing יכול להקטין את כמות הדאטא שמועבר בין shardים.
- ביצוע פעולת JOIN על מספר shardים מורכבת יותר.
- sharding מוסיף חומרה ומורכבות.
מקורות וקריאה נוספת
דנורמליזציה (Denormalization)
דנורמליזציה שואפת לשפר ביצועים של קריאות על חשבון חלק מהביצועים של הכתיבות. עותקים מיותרים (משוכפלים באופן מכוון, Redundant) של הדאטא נכתבים במספר טבלאות שונות כדי להימנע מביצוע JOINים יקרים. חלק מה-RDBMSים כמו PostgreSQL ו-Oracle תומכים ב-materialized views אשר דואגים לשמירה של מידע מיותר ושמירת עותקים מיותרים עקביים.
כאשר הדאטא מבוזר באמצעות טכניקות כמו פדרציה או חלוקה, ניהול JOINים בין ריכוזי מידע שונים מגדיר את המורכבות. דנורמליזציה יכולה לייתר את הצורך לבצע JOINים מורכבים.
ברוב המערכות, כמות הקריאות גדולה בהרבה מכמות הכתיבות, ביחס של 100:1 ואף 1000:1. קריה יכולה להוביל לביצוע JOIN מורכב ויקר, מה שעולה בביצוע פעולות דיסק זמן רב.
חסרונות: דנורמליזציה
- הדאטא משוכפל.
- אף שדנורמליזציה משפרת קריאות, היא דורשת שכבת אילוצים (constraints) וחוקים מסוימים כדי לשמור על עקביות העותקים — מה שמסבך את תכנון ה-DB.
- במערכת עם עומס כתיבה כבד ייתכן שדנורמליזציה דווקא תפגע בביצועים.
מקורות וקריאה נוספת
SQL Tuning
התחום של SQL Tuning הוא רחב, ונכתבו עליו לא מעט ספרים. חשוב לבצע Benchmark ו-Profile כדי לדמות עומסים ולגלות צווארי-בקבוק.
- Benchmark – סימולציית עומס כבד באמצעות כלים כמו ab.
- Profile – הפעלת כלים כגון Slow Query Log למעקב אחר בעיות ביצועים.
התוצאות של השימוש בכלים אלו עשויה להוביל לאופטימיזציות הבאות:
הידוק הסכימה (Tighten up the schema)
- MySQL כותב לדיסק בבלוקים עוקבים, לגישה מהירה.
- השתמש ב-
CHARבמקוםVARCHARלשדות קבועי-אורך. code>CHAR מאפשר גישה אקראית מהירה; ב-VARCHARצריך לחפש את סוף-המחרוזת. - השתמש ב-
TEXTלמקטעי טקסט גדולים (למשל פוסטים של בלוג); מאפשר גם חיפושים בוליאניים. השדה מאחסן מצביע על הדיסק שמטרתו לאתר את בלוק הטקסט. - השתמש ב-
INTלמספרים עד 232 (≈ 4 מיליארד). - השתמש ב-
DECIMALלערכים כספיים – כדי להימנע משגיאות Floating Point. - הימנע מאחסון
BLOB-ים גדולים; שמור רק את המיקום שלהם. VARCHAR(255)– המספר שמנצל בתים בצורה מיטבית בחלק מה-RDBMS-ים.- הגדר
NOT NULLכשאפשר כדי לשפר ביצועי חיפוש.
השתמש באינדקסים טובים (Use good indices)
- עמודות הנשלפות באמצעות פקודות כמו
SELECT,GROUP BY,ORDER BY,JOINיכולות להיות מהירות יותר עם אינדקסים. - אינדקסים מיוצגים בדרך-כלל כ-B-Tree מאוזן: שומר על הדאטא ממוין, ומאפשר חיפוש/הוספה/מחיקה בזמן לוגריתמי.
- אינדקס שומר את הנתונים בזיכרון – אבל צורך יותר מקום.
- כתיבות עלולות להיות איטיות יותר כי צריך לעדכן גם את האינדקס.
- בעת טעינת נתונים גדולה ייתכן שיותר מהיר להשבית אינדקסים, לטעון את הנתונים ואז לבנות את האינדקסים מחדש.
מניעת JOIN יקר
- לשקול דנורמליזציה כאשר הביצועים דורשים זאת.
חלוקה לטבלאות (Partitioning)
- חלוקה לטבלאות (Partitioning) מאפשרת לשמור את ה־hot spots (אזורים “חמים” בטבלה, כלומר רשומות שנקראות/נכתבות הכי הרבה) במחיצה קטנה שנשארת בזיכרון, ולכן שאילתות על הנתונים העדכניים רצות מהר יותר ומעמיסות פחות על הדיסק.
כוונון Query Cache
- במקרים מסוימים, query cache עלול לגרום לבעיות ביצועים.
מקורות וקריאה נוספת
- Tips for optimizing MySQL queries
- Is there a good reason i see VARCHAR(255) used so often?
- How do null values affect performance?
- Slow query log
NoSQL
לעומת SQL קלאסי, NoSQL הוא אוסף של מבני נתונים הנשמרים בתור Key-Value Store, Document Store, Wide Column Store או Graph Database.
הנתונים מנורמלים פחות, ופעולות JOIN מבוצעות לרוב בקוד האפליקציה עצמה.
רוב האחסונים מסוג NoSQL אינם תומכים בטרנזקציות ACID מלאות ומספקים עקביות לא מיידית.
מקובל לסמן את מאפייני NoSQL בראשי התיבות BASE (תווך שימוש במשפט CAP, תכונות BASE מתעדפות זמינות (A) על פני עקביות (C)):
- Basically Available – המערכת מבטיחה זמינות.
- Soft State – מצב המערכת עשוי להשתנות עם הזמן, גם ללא קלט.
- Eventual Consistency – המערכת תהפוך עקבית בסופו של דבר, בהנחה שלא מתקבל קלט נוסף בתקופה זו.
מעבר לבחירה בין SQL ל-NoSQL, חשוב להבין איזה סוג NoSQL מתאים ביותר לשימוש שלך. נדון בסוגים Key-Value Stores, Document Stores, Wide Column Stores ו-Graph Databases.
אחסון Key-Value
הפשטה: Hash Table
אחסון Key-Value לרוב מאפשר קריאות וכתיבות ב-O(1) ומגובה באמצעות זיכרון או SSD. ניתן לשמור מפתחות בסדר לקסיקוגרפי, מה שמאפשר שליפה יעילה של טווחי המפתחות. אחסון זה מאפשר תמיכה ב-metadadta עם ערכים.
אחסון זה מספק ביצועים גבוהים ולרוב בשימוש עבור מודלי דאטא פשוטים או לדאטא שמשתנה במהירות, כמו שכבת cache in-memory. כיוון שסוגי אחסון זה מציעים סט מצומצם של פעולות, המורכבות נמצאת בשכבת האפלקציה אם נדרשות פעולות נוספות.
אחסון זה הוא הבסיס למערכות מורכבות יותר כמו document store ובמקרים מסוימים גם graph db.
מקורות וקריאה נוספת: אחסון Key-Value
אחסון Document
הפשטה: אחסון Key-Value שבו הערך הוא מסמך
אחסון Document מתרכז סביב מסמכים (XML, JSON, binary, etc.) כאשר מסמך שומר את כל המידע שקשור לאובייקט מסוים. אחסון זה מספק API או query language כדי לתשאל על בסיס המבנה הפנימי של המסמך עצמו. נשים לב, כי הרבה אחסונים מסוג Key-Value כוללים פיצ'רים כדי לעבוד עם ה-metadata של ה-value, מה שמטשטש את הגבול בין שני סוגי אחסון אלו.
על בסיס המימוש הספציפי מאחורי הקלעים, מסמכים מאורגנים לפי אוספים, תגים, metadata או תיקיות. למרות שמסמכים יכולים להיות מאורגנים או מקובצים יחדיו, יכולים להיות להם שדות שונים לחלוטין אחד מהשני.
אחסונים כמו MongoDB ו-CouchDB מציעים שפה דמוית SQL על מנת לבצע שאילתות מורכבות. DynamoDB תומך גם ב-Key-Value וגם במסמכים.
אחסונים אלו מספקים גמישות גבוהה ולרוב בשימוש עבור דאטא שמשתנה בתדירות גבוהה.
מקורות וקריאה נוספת: אחסון Document
אחסון Wide Column

Source: SQL & NoSQL, a brief history
הפשטה: Map מקונן מסוג
ColumnFamily<RowKey, Columns<ColKey, Value, Timestamp>>
אחסון Wide Column עובד עם יחידת דאטא בסיסית שהיא עמודה (זוג שם/ערך). עמודות מקובצות תחת column families (כמו טבלת SQL). Super column families הן אוסף של column families. אפשר לגשת לכל עמודה בנפרד עם row key, כאשר עמודות בעלות אותו row key יוצרות שורה. כל ערך מכיל timestamp עבור גרסאות ופתרון קונפליקטים.
דוגמאות: Google הציגה את Bigtable כאחסון הראשון מסוג זה. זה השפיע על פרויקט הקוד הפתוח HBase (באקוסיסטם Hadoop) ו-Cassandra של Facebook.
מערכות כמו Bigtable, HBase ו-Cassandra שומרות מפתחות בסדר לקסיקוגרפי, וכך מאפשרות שליפת טווחי מפתחות ביעילות.
אחסונים אלו מציעים זמינות גבוהה, וסקילביליות גבוהה. לרוב משתמשים בהם לאחסון דאטאסטים מאוד גדולים.
מקורות וקריאה נוספת: אחסון Wide Column
אחסון Graph

הפשטה: גרף
ב-DB גרפי כל צומת (Node) הוא רשומה, וכל קשת (Arc/Edge) היא קשר בין שני צמתים.
ה-DB מותאם לייצוג קשרים מורכבים – עם הרבה מפתחות זרים (Foreign Keys) או יחסי Many-to-Many.
אחסון זה מאפשר ביצועים גבוהים למודלים עם יחסים מורכבים, למשל כמו רשת חברתית. הטכנולוגיה הזו יחסית חדשה ופות נפוצה; ייתכן קושי למצוא כלי פיתוח ומשאבים. הרבה אחסונים מסוג זה נגישים רק באמצעות REST APIs.
מקורות וקריאה נוספת: Graph
מקורות וקריאה נוספת: NoSQL
- Explanation of base terminology
- NoSQL databases a survey and decision guidance
- Scalability
- Introduction to NoSQL
- NoSQL patterns
SQL or NoSQL

Source: Transitioning from RDBMS to NoSQL
-סיבות לשימוש בSQL:
- נתונים עם מבנה קבוע
- סכמה ברורה עם אילוצים וטיפוסים
- דאטא עם קשרי Foreign Key ו־Many-to-Many
- צורך בביצוע JOIN-ים מורכבים
- טרנזקציות (עקרונות ACID)
- תבניות ברורות לביצוע Scaling
- אקו־סיסטם ענק של כלים, קוד וקהילה
- חיפושים לפי אינדקס מהירים מאוד
סיבות לשימוש ב-NoSQL:
- דאטא שהוא מובנה באופן חלקי
- סכמה דינמית או גמישה
- דאטא ללא relations
- אין צורך ב־JOIN־ים מורכבים
- אחסון TB או PB של דאטא
- פעולות רבות של כתיבה וקריאה בשנייה
- כמות גדולה של פעולות דיסק בשנייה
דאטא לדוגמה שמתאים מאוד עבור NoSQL:
- Rapid ingest of clickstream and log data
- Leaderboard or scoring data
- Temporary data, such as a shopping cart
- Frequently accessed ('hot') tables
- Metadata/lookup tables
מקורות וקריאה נוספת: SQL or NoSQL
מטמון (Cache)
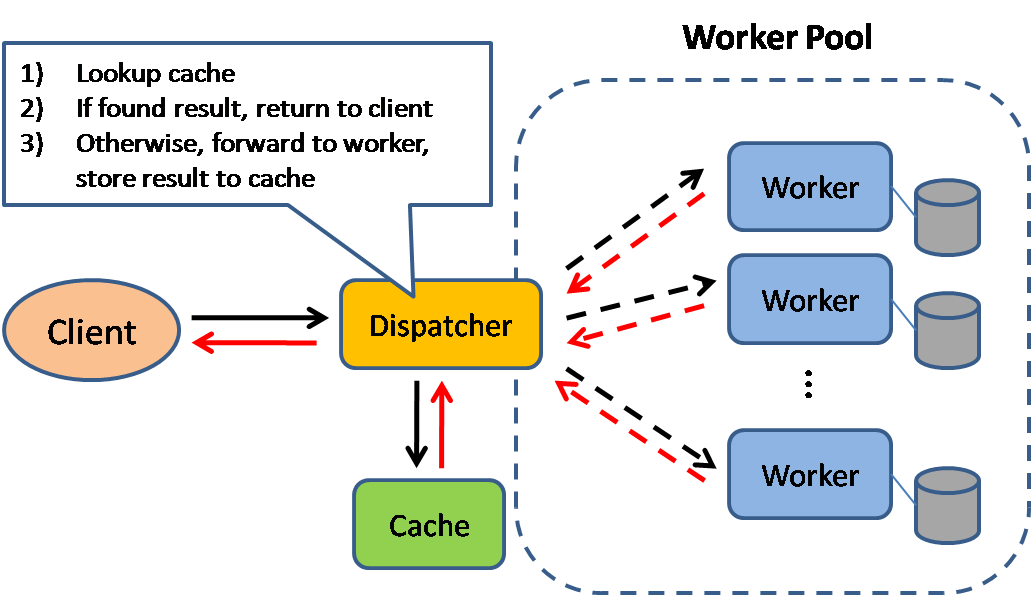
Source: Scalable system design patterns
שמירת נתונים ב-cache משפרת את זמן טעינת הדפים, ומפחיתה את העומס על השרתים ועל ה-DBים. במודל זה, השרת מחפש האם הבקשה שהגיעה כבר נעשתה בעבר, ומנסה למצוא תוצאה מוכנה, כדי לחסוך את זמן העיבוד על אותה ההודעה מחדש.
מסדי נתונים לרוב מרוויחים מהתפלגות אחידה של קריאות וכתיבה על פני החלוקות שלהם (partitions). פריטים שניגשים אליהם הרבה יכולים ליצור זינוק בקריאות וכתיבה לחלוקה מסוימת וליצור צווארי-בקבוק. כאשר שמים שכבת cache לפני ה-DB, פיקים קיצוניים בתעבורה נספגים בזיכרון המהיר של המטמון ולא מעמיסים על ה-DB.
מטמון בצד לקוח
מטמון יכול להיות ממוקם בצד הלקוח (מערכת ההפעלה או הדפדפן), צד השרת, או בשכבה נפרדת.
מטמון CDN
ניתן להסתכל על CDN גם בתור שכבה של מטמון.
מטמון בשרת
פרוקסי הפוך ומנגנוני cache כמו Varnish יכולים להנגיש תוכן סטטי ודינמי ישירות. שרתי web יכולים גם לבצע cache לבקשות כדי להחזיר תשובות בלי צורך להגיע עד לשרתי האפליקציה.
מטמון במסד נתונים
ה-DB לרוב כולל רמה מסוימת של caching באופן דיפולטי, אשר מאופטמת למקרה הכללי. ביצוע כיוונון להגדרות האלה עבור תבניות שימוש ספציפיות יכול להאיץ את הביצועים.
מטמון באפליקציה
מטמון in-memory כמו Memcached ו-Redis מהווים אחסון key-value בין האפליקציה ובין ה-DB. כיוון שהדאטא מוחזק ב-RAM, זה הרבה יותר מהיר מ-DB טיפוסי שם הדאטא נשמר על הדיסק. ה-RAM יותר מוגבל מהדיסק, לכן אלגוריתמים של cache invalidation כמו least recently used (LRU) עוזרים "לזרוק" את הפריטים שלא נגעו בהן זמן רב (cold) ולהשאיר את הנתונים הרלוונטיים (hot).
ל-Redis יש את הפיצ'רים הבאים:
- אופציה פרסיסטנטית
- מבני נתונים כמו sorted sets ו-lists
יש הרבה רמות שניתן לבצע בהן cache, והן מתחלקות לשתי קטגוריות עיקריות: database queries ו-objects:
- Row level
- Query-level
- Fully-formed serializable objects
- Fully-rendered HTML
באופן כללי, עדיף להימנע מביצוע caching לקבצים, דבר המקשה על cloning - שכפול, ועל auto-scaling - הוספה או הורדה של מכונות.
מטמון ברמת שאילתה
בכל פעם שמבצעים שאילתה ל-DB, נעשה hash על השאילתה בתור key, ונאחסן את התוצאה שלה ל-cache. הגישה הזאת סובלת מבעיות של תוקף:
- קשה למחוק תוצאה שמורה של שאילתה מורכבת (באילו טבלאות הוא משתמש)
- שינוי קטן ב-DB מחייב מחיקה של כל השאילתות הרלוונטיות שנשמרו, התוצאות כבר לא מעודכנות
מטמון ברמת אובייקט
במקום לשמור תוצאה של שאילתה, נחשוב על הנתונים כמו על "אובייקט" בקוד. האפליקציה שולפת את המידע מה-DB ומרכיבה ממנו מופע שמתאר אותו תוך שימוש ב-class כלשהו:
- יש להסיר את האובייקט מה-cache אם אחד מהשדות שלו השתנה
- מאפשר עיבוד אסינכרוני: תהליכים ברקע יכולים להרכיב אובייקטים על ידי הדבר האחרון שנמצא ב-cache
הצעות לדברים שכדאי לבצע להם cache:
- User sessions
- Fully rendered web pages
- Activity streams
- User graph data
מתי לעדכן את ה-cache?
כיוון שאפשר לאחסן רק כמות מוגבלת של מידע ב-cache, יש לבחור באסטרטגיית עדכון ופינוי המקום ב-cache שמתאימה ביותר עבור המערכת.
אסטרטגיית Cache-Aside
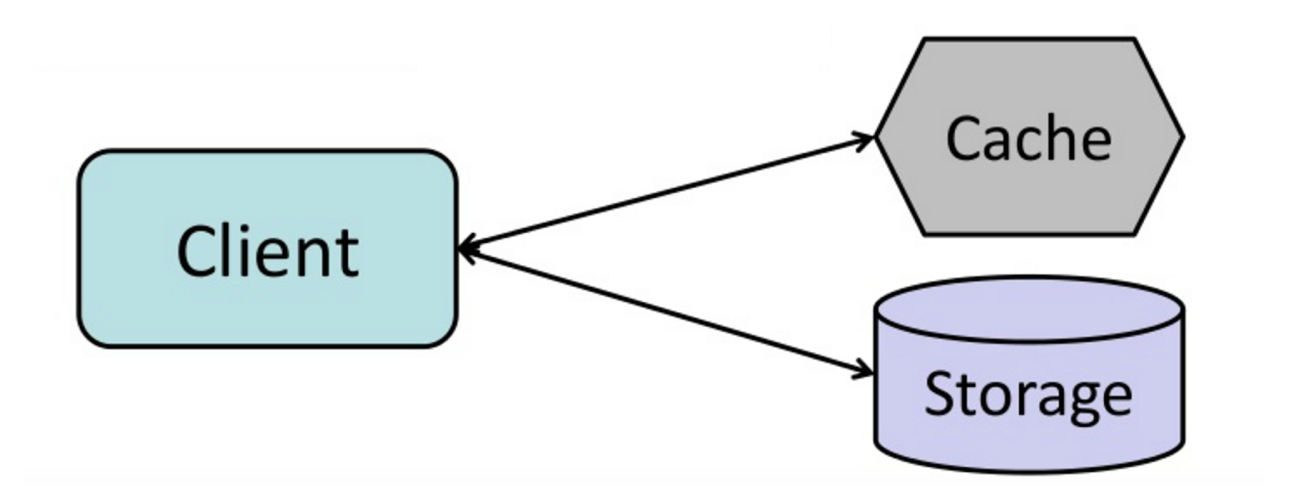
Source: From cache to in-memory data grid
האפליקציה אחראית לבצע קריאה וכתיבה מול האחסון. ה-cache לא מדבר עם האחסון ישירות. האפליקציה עושה את הדברים הבאים:
- חיפוש הרשומה ב-cache, מה שמוביל ל-cache miss
- טוענים את הרשומה מהאחסון
- שומרים את התוצאה ב-cache
- מחזירים את הרשומה ללקוח
def get_user(self, user_id):
user = cache.get("user.{0}", user_id)
if user is None:
user = db.query("SELECT * FROM users WHERE user_id = {0}", user_id)
if user is not None:
key = "user.{0}".format(user_id)
cache.set(key, json.dumps(user))
return user
למשל Memcached יכול להיות בשימוש בקטע קוד מהסוג הזה, האפליקציה היא זו שקובעת מתי לקרוא ולכתוב ל-cache. אחרי שהפריט נכתב ל-cache, כל קריאה חוזרת אליו מהירה במיוחד. אסטרטגייה זו נקראת גם lazy loading. רק מידע שנעשתה אליו גישה נכנס ל-cache, מה שמונע שמירה של הרבה דאטא שאין בו שימוש.
חסרונות: cache-aside
- כל cache miss עולה לנו ב-3 שלבים, מה שיכול לגרום לעיכוב משמעותי.
- הדאטא יכול להתיישן אם הוא מתעדכן ב-DB. הרשומה ב-RAM כבר לא רלוונטית. אפשר לקבוע TTL קצר או לעבור לאסטרטגיה של write-through.
- כאשר שרת ה-cache קורס, הוא מוחלף באחד חדש שעולה ריק מאפס, מה שגורם ל-latency גבוה.
אסטרטגיית Write-Through

Source: Scalability, availability, stability, patterns
האפליקציה מתייחסת אל ה-cache כאחסון המרכזי, מבצעת קריאות וכתיבות מולו, כאשר ה-cache אחרי לבצע את הקריאות והכתיבות מול ה-DB:
- האפליקציה מוסיפה או מעדכנת רשומה ב-cache
- ה-cache מסנכרן כל כתיבה ל-DB
- הפעולה חוזרת למשתמש
Application code:
set_user(12345, {"foo":"bar"})
Cache code:
def set_user(user_id, values):
user = db.query("UPDATE Users WHERE id = {0}", user_id, values)
cache.set(user_id, user)
אסטרטגיה זו איטית יותר בשל ביצוע ה-write (שתי כתיבות במקום אחת), אבל קריאות שיקרו בהמשך של הדאטא שזה עתה נכתב יהיו מהירות. המשתמשים לרוב יותר סבלניים לגבי שיהוי כאשר מעדכנים את הדאטא לעומת קריאה שלו. הדאטא ב-cache תמיד עדכני.
חסרונות: write through
- כאשר עולה node חדש של ה-cache הוא לא יכיר אף רשומה עד שהיא לא תתעדכן ב-DB, המערכת צריכה קודם לבצע עדכונים לאותם הערכים. שילוב של cache-aside עם write-through יכול לצמצם את הבעיה - אם אין ערך, האפליקציה טוענת מה-DB ושומרת ב-cache, ואז העדכון נכנס גם ל-cache וגם ל-DB.
- חלק גדול מהנתונים שנכתבים לעולם לא ייקראו, כל כתיבה נשמרת ל-cache ותופסת RAM יקר בלי שבהכרח יש בה שימוש. אפשר למנוע את בזבוז הזיכרון באמצעות TTL על ערכים שאינם נקראים. הערכים שעדיין "חמים" יתעדכנו מחדש ב-TTL בכל קריאה או כתיבה.
אסטרטגיית Write-Behind/Back

Source: Scalability, availability, stability, patterns
האפליקציה מבצעת את הפעולות הבאות:
- הוספה או עדכון של רשומה ב-cache.
- כתיבת הרשומה באופן אסינכרוני ל-DB, כך זמן הכתיבה שנתפס בעיני המשתמש קצר מאוד, מפני שהחלק האיטי (לדיסק) נעשה ברקע.
חסרונות: write-behind
- יכול להיות אובדן מידע אם ה-cache נופל לפני שהכתיבה האסינכרונית ל-DB הסתיימה, ואז הרשומות נעלמו לנצח.
- יותר מורכב לממש write-behind מאז לממש את האסטרטגיות הקודמות כמו cache-aside או write-through.
אסטרטגיית Refresh-Ahead

Source: From cache to in-memory data grid
אפשר לקנפג את ה-cache כך שהוא ירענן כל פריט שניגשו אליו לאחרונה לפני שתפוג תקופת ה-TTL שלו (יבצע fetch מול ה-DB).
אם המערכת יודעת לחזות בצורה טובה אילו פריטים יבוקשו שוב בקרוב, נקבל latency נמוך יותר משיטות read-through רגילות: המשתמש יקבל תשובה מ-cache שכבר עבר עדכון ברקע (ואין cache miss).
חסרונות: refresh-ahead
- חיזוי לא מדויק של פריטים שיידרשו בעתיד יכול לגרום לרענון מיותר, ובזבוז של RAM וחיבורים ל-DB, מה שעלול לגרום לתוצאות איטיות יותר מאשר בלי לבצע refresh-ahead.
חסרונות: cache
- חייבים לשמר עקביות בין ה-cache ומקור המידע האמיתי (ה-DB) באמצעות cache invalidation, כללים הקובעים מתי מוחקים או מרעננים ערכים ב-cache.
- cache invalidation הוא אתגר לא פשוט, יש מורכבות נוספת להבנה מתי בדיוק ערך ב-cache הוא כבר לא עדכני.
- נדרשים לבצע שינויים בקוד ובתשתית להוספת רכיבים כמו Redis או Memcached.
מקורות וקריאה נוספת
אסינכרוניות (Asynchronism)

Source: Intro to architecting systems for scale
ביצוע פעולות באופן אסינכרוני עוזר לקצר זמני תגובה לבקשות עצמן. פעולות כבדות אינן מבוצעות ישירות אלא מתווספות לתור משימות, כאשר התשובה חוזר כמעט מיד. ברקע, המשימה מתבצעת מאוחר יותר. משימות שלוקחות זמן רב יכולות להתבצע מבעוד מועד, כמו aggregation תקופתי של דאטא. הנתונים כבר מוכנים מראש והשליפה תהיה מהירה.
תורי הודעות (Message Queues)
תורי הודעות מקבלים, מחזיקים, ושולחים הודעות. אם פעולה איטית מידי לביצוע באופן סינכרוני, אפשר להשתמש בתור הודעות באופן הבא:
- האפליקציה מקבלת בקשת משתמש לביצוע פעולה כבדה, היא בונה הודעה ומכניסה אותה לתור. המשתמש מקבל תשובה על כך שהבקשה התקבלה והיא בתהליך.
- תהליך worker רץ ברקע ומאזין לתור, שולף את ההודעה ומתחיל לבצע את הפעולה. כשהוא מסיים, הוא מאשר לתור שההודעה טופלה בהצלחה, ומעדכן את האפליקציה.
המשתמש לא נתקע (blocked) והעבודה מתבצעת ברקע. בזמן הזה, המשתמש יכול לבצע פעולות כדי לגרום לכך להיראות כאילו הפעולה בוצעה. למשל, אם מדובר על העלאה של ציוץ (tweet), הוא יכול להתרפסם מיידית ב-timeline של המשתמש, אבל יקח זמן עד שהוא באמת יישלח לכל העוקבים (ייתכן פער של כמה שניות).
דוגמאות לסוגי תורים:
-
Redis is useful as a simple message broker but messages can be lost.
-
RabbitMQ is popular but requires you to adapt to the 'AMQP' protocol and manage your own nodes.
-
Amazon SQS is hosted but can have high latency and has the possibility of messages being delivered twice.
תורי משימות (Task Queues)
תורי משימות מקבלים משימות לצד המידע הרלוונטי שלהן, מריצים אותן, ושולחים את התוצאות. הם יכולים לתמוך ב-scheduling, כלומר להריץ משימה כל זמן מסוים או בשעה קבועה. בנוסף, הם יכולים להריץ משימות כבדות מבחינה חישובית ברקע.
- Celery has support for scheduling and primarily has python support.
Back Pressure
אם התור מתחיל לגדול באופן משמעותי מעבר לקצב שבו ה-workers מסוגלים לעבד, גודל התור יכול להיות מעבר למה שפנוי לנו בזיכרון, מה שיגרום ל-cache misses, יותר קריאות מהדיסק, וביצועים נמוכים יותר. Back pressure יכול לעזור באמצעות הגדלת גודל התור, מה ששומר על קצב הטיפול בבקשות לכאלו שכבר בתוך התור. אם התור מתמלא, השרת מפסיק לקבל עבודות חדשות ומחזיר ללקוח שגיאת HTTP 503 (עסוק). הלקוח יכול לנסות שוב לאחר זמן המתנה הולך וגדל כמו exponential backoff.
חסרונות: asynchronism
- במצבים שבהם מדובר בחישובים זולים במיוחד, או בתהליכים הדורשים עיבוד בזמן אמת, עדיף לעיתים לבצע את הפעולה באופן סינכרוני, משום שהוספת תור למערכת עלולה להוסיף עיכובים ומורכבות מיותרת.
מקורות וקריאה נוספת
תקשורת

{kind=link}
פרוטוקול HTTP
פרוטוקול HTTP מאפשר ללקוח ולשרת אינטרנט להחליף מידע בפורמט מוגדר. הוא מבוסס על מבנה של request/response: הלקוח/הדפדפן שולח בקשה לתוכן או פעולה מסוימת, והשרת מחזיר תגובה הכוללת את הנתונים המבוקשים, לצד קוד סטטוס שמצהיר אם הבקשה הצליחה, נכשלה, או הופנתה למקום אחר. פרוטוקול זה הוא self-contained, כלומר כל המידע הנחוץ - הכותרות, סוג הבקשה, הנתונים - עובר כחבילה אחת. לכן החבילות האלה יכולות לעבור דרך router, load balancer בלי שהמתווכים יידרשו להבין את הלוגיקה. לאורך הדרך אותם גורמי ביניים יכולים להוסיף הצפנה, לדחוס נתונים, מבלי שהפרוטוקול עצמו ייפגע.
בקשת HTTP טיפוסית מכילה verb (מתודה) ו-resource (נקודת קצה). דוגמאות:
| Verb | Description | Idempotent* | Safe | Cacheable |
|---|---|---|---|---|
| GET | Reads a resource | Yes | Yes | Yes |
| POST | Creates a resource or trigger a process that handles data | No | No | Yes if response contains freshness info |
| PUT | Creates or replace a resource | Yes | No | No |
| PATCH | Partially updates a resource | No | No | Yes if response contains freshness info |
| DELETE | Deletes a resource | Yes | No | No |
*ניתן לבצע מספר פעמים את אותה הבקשה ולקבל את אותה התוצאה כל פעם.
פרוטוקול זה הוא בשכבת האפליקציה, והוא מסתמך על פרוטוקולים בשכבות נמוכות יותר כמו TCP ו-UDP.
מקורות וקריאה נוספת
פרוטוקול TCP

Source: How to make a multiplayer game
פרוטוקול זה הוא מבוסס מעל IP network. החיבור נבנה ונסגר באמצעות handshake. כל הפקטות שנשלחות מובטחות להגיע ליעד בדיוק בסדר המקורי שבו הן נשלחו, ובאופן תקין (uncorrupted):
- Sequence numbers and checksum fields for each packet
- Acknowledgement packets and automatic retransmission
אם השולח לא מקבל תשובה תקינה בתוך פרק זמן קצוב, הוא מניח שהמקטע אבד ומשדר אותו שוב. אם יש מספר timeouts כמה פעמים ברצף, אז החיבור נסגר. TCP מממש גם flow control וגם congestion control על מנת לפקח על קצב הנתונים. ההבטחות הללו מוסיפות תזמונים, חישובים, וחבילות בקרה, מה שעלול לגרום לעיכובים וליצור תעבורה פחות מהירה מאשר UDP.
כדי לאפשר throughput מהיר, שרתים שומרים הרבה חיבורי TCP פתוחים, מה שמוביל לצריכת זיכרון גבוהה. הבעיה מחריפה כאשר אותו שרת מפעיל חיבורים נפרדים בין התהליכים שלו לבין שירותים פנימיים אחרים, כמו לדוגמה אל שרת memcached. ביצוע Connection pooling, שמירת אוסף חיבורים פתוחים המשותפים בין כל ה-threads, יכול לסייע ומצמצם את מספר החיבורים האמיתיים וחוסך זיכרון. בנוסף, ניתן לעבור ל-UDP היכן שניתן, שם אין שמירה של חיבור.
פרוטוקול TCP שימושי לאפליקציות שדורשות אמינות גבוהה, על פני מהירות וזמן תגובה מיידי. דוגמאות: שרתי HTTP, FTP, SMTP, SSH או MySQL בוחרים ב-TCP. שיקולים לבחירה בפרוטוקול זה על פני UDP:
- אנו זקוקים שכל הנתונים יגיעו בשלמותם, ללא אובדן מידע
- נרצה להתאים את קצב הנתונים ברשת באופן אוטומטי, בלי להציף את הקו
פרוטוקול UDP

Source: How to make a multiplayer game
בפרוטוקול זה אין חיבור קבוע בין הלקוח לשרת. כל חבילה (Datagram) נשלחת בנפרד, ללא מעקב אחרי מה שכבר נשלח. החבילות יכולות להגיע ליעד בסדר שונה, או בכלל לא. אין תמיכה ב-congestion control. עם זאת, כיוון שאין את כל ההבטחות שכלולות ב-TCP, ה-overhead קטן מאוד ולכן UDP יעיל ומהיר יותר. האפליקציה צריכה להתמודד בעצמה עם איבוד חבילות וסדר החבילות.
ב-UDP מתאפשר שידור (broadcast) - שליחת חבילה אחת לכל המכשירים של אותו ה-subnet. זה שימושי בשילוב עם DHCP כיוון שבתחילת התהליך המחשב עדיין לא קיבל כתובת IP, ולכן אינו יודע למי לפנות ישירות. הוא משדר הודעה ברשת וכל שרת DHCP שומע את ההודעה, בוחר להשיב ומציע כתובת IP. ב-TCP זה לא היה עובד, כי שם אנו נדרשים לדעת כתובת יעד ספציפית.
פרוטוקול זה הינו פחות אמין אבל עובד בצורה טובה במקרים של real time כמו VoIP, וידאו צ'אט, streaming, ומשחקים מרובי משתתפים. מתי הוא עדיף על TCP?
- אנו זקוקים ל-latency נמוך ביותר
- דאטא שמגיע באיחור גרוע יותר מאיבוד הדאטא
- נרצה לממש מנגנון תיקון שגיאות משלנו
מקורות וקריאה נוספת: TCP and UDP
פרוטוקול RPC

Source: Crack the system design interview
ב-RPC, לקוח גורם לריצה של פונקציה במרחב כתובות שונה, לרוב על שרת מרוחק, כאילו הייתה פונקציה מקומית בקוד שלו. הלקוח פשוט קורא לפונקציה, ומאחורי הקלעים ישנה ספריה אשר מטפלת באריזה (serialization) של הפרמטרים, שליחת הבקשה ב-TCP, קבלת התשובה ותרגומה לאובייקט. RPC הינו לרוב איטי יותר ופחות אמין מאשר קריאה מקומית, לכן חשוב לסמן קריאות כאלו כ-RPC כדי שמפתחים יבינו שהן עלולות להיכשל או להתעכב. תשתיות נפוצות כוללות את Protobuf, Thrift, Avro.
פרוטוקול זה מבוסס על בקשה-תגובה:
- תוכנית הלקוח - הקוד קורא לפונקציית ה-stub של ה-client. הפרמטרים נדחפים למחסנית כמו בקריאה לוקאלית רגילה לפונקציה (LPC).
- client stub - הספריה אורזת את מזהה הפונקציה ואת הארגומנטים ומקודדת אותם בפורמט שניתן להעביר לצד השני.
- תקשורת בצד הלקוח - מערכת ההפעלה שולחת את ההודעה אל השרת
- תקשורת בצד השרת - מערכת ההפעלה מקבלת את ההודעה ומעבירה אותה ל-server stub המתאים.
- server stub - מפענחת את המזהה ואת הארגומנטים, קוראת לפונקציה האמיתית בקוד השרת עם אותם הפרמטרים.
- השרת אורז את התוצאה ומחזיר אותה ללקוח על פי הצעדים הללו בסדר הפוך.
קריאות RPC לדוגמה:
GET /someoperation?data=anId
POST /anotheroperation
{
"data":"anId";
"anotherdata": "another value"
}
פרוטוקול מתמקד בהגדרת התנהגות של פונקציות כאילו הן חלק מהממשק המקומי של השפה. הקריאה עובדת מאחורי הקלעים לשרת אחר, אבל למפתח זה נראה כמו פונקציה רגילה. RPC מאפשר גם שליטה מוחלטת על הפונקציונליות והתקשורת, ומתאים לפיתוח מערכת פנימית. נרצה לבחור בספריה משלנו (SDK) כאשר:
- ישנה שפת יעד קבועה
- נרצה לשלוט באיך שניגשים ללוגיקה שלנו
- נרצה לשלוט בלוגיקה של טיפול בשגיאות
- ביצועים וחווית המשתמש בקצה היא שיקול מרכזי
ממשקים שעוקבים אחרי פרוטוקול REST נוטים להיות יותר בשימוש עבור APIים פומביים.
חסרונות: RPC
- תלות חזקה בין הלקוח לשרת
- צריך להגדיר API נפרד לכל פעולה חדשה
- קשה יותר לדבג RPC
- לא קל בהכרח לעשות שימוש בטכנולוגיות נוכחיות בלי התאמות נוספות. יש לוודא שהקריאות עוברות caching כמו שצריך על שרתים כמו Squid
ממשק REST
בממשק REST הלקוח מבקש סט מסוים של משאבים המנוהלים על ידי השרת. השרת מספק ייצוג של המשאבים ופעולות שניתן לעשות עליהם. כל התקשורת היא stateless ו-cacheable. יש 4 תכונות של ממשק RESTful:
- זיהוי משאבים (URI ב-HTTP) - כל דבר שה-API חושף מקבל כתובת URL אחידה.
- הפעולה נקבעת לפי הפועל והכותרות - הפעלים השונים ב-HTTP בתוספת לכותרות ולגוף הבקשה מגדירים מה יקרה. עקרון זה מפריד בין ה-URI /orders/7 לבין הפעולה GET/PUT/PATCH.
- סטטוס שגיאות סטנדרטי - אין צורך להמציא קודי שגיאות, משתמשים בסטטוסים של HTTP כמו 404, 200 וכו'.
- HATEOAS - ממשק HTML עבור HTTP, התשובה עצמה כוללת קישורים לפעולות הבאות האפשריות.
קריאות REST לדוגמה:
GET /someresources/anId
PUT /someresources/anId
{"anotherdata": "another value"}
הפרוטוקול מתמקד בחשיפת הנתונים בתור משאבים (בשונה מהפעלת פונקציות ב-RPC) באמצעות כתובת URL קבועה. הלקוח שולח בקשות HTTP סטנדרטיות והשרת מחזיר את התשובה המתאימה. זה מאפשר coupling נמוך בין הלקוח לשרת: הלקוח רק צריך לדעת אילו URI-ים קיימים ואילו פעלים מותר להפעיל (GET, POST), אין תלות בשפת התכנות של השרת או בספריות מיוחדות. REST מספק ממשק אחיד לייצוג הפעולות - representation through headers. כיוון שהוא stateless, קל לפרוס עותקים רבים שלו מאחורי load balancer ולבזר את העומסים.
Disadvantage(s): REST
- כיוון ש-REST מתמקד שחשיפת נתונים בתור משאבים, אם הדאטא לא מסתדר באופן טבעי בהיררכיה הזאת, זה יכול פחות להתאים. למשל, להחזיר את כל הרשומות שהתעדכנו מהשעה האחרונה, עונה על סט מסוים של אירועים שלאו דווקא קל לבטא בתור path. עם REST, ניתן לשלב URI path, query parameters, ואולי גם להשתמש ב-request body.
- REST מתבסס לרוב על כמה פעולות ספציפיות (GET, POST, PUT, DELETE, PATCH) שלא תמיד מתאים בדיוק לשימוש המבוקש. פעולה כמו "העבר מסמכים שפג תוקפם לארכיון" אינה יושבת בצורה קלאסית על אחת הפקודות.
- כדי לשלוף משאב מורכב שכולל היררכייה מסועפת, יש לבצע מספר בקשות הולכות וחוזרות בין הלקוח לשרת. למשל, כדי לקבל פוסט עם תגובות מסוימות, הלקוח צריך לבצע כמה קריאות נפרדות (קודם לפוסט, ואז לתגובות). עבור אפליקציות mobile עם תנאי חיבוריות משתנים, כמות הבקשות הללו אינה רצויה.
- עם הזמן, שדות נוספים יכולים להתווסף לתגובה שחוזרת מה-API, ומשתמשים ישנים יכולים לקבל מידע שאינם זקוקים לו. הדבר מעמיס על גודל ה-payload ובכך על ה-latency.
השוואה בין קריאות RPC ובין REST
| Operation | RPC | REST |
|---|---|---|
| Signup | POST /signup | POST /persons |
| Resign | POST /resign { "personid": "1234" } |
DELETE /persons/1234 |
| Read a person | GET /readPerson?personid=1234 | GET /persons/1234 |
| Read a person’s items list | GET /readUsersItemsList?personid=1234 | GET /persons/1234/items |
| Add an item to a person’s items | POST /addItemToUsersItemsList { "personid": "1234"; "itemid": "456" } |
POST /persons/1234/items { "itemid": "456" } |
| Update an item | POST /modifyItem { "itemid": "456"; "key": "value" } |
PUT /items/456 { "key": "value" } |
| Delete an item | POST /removeItem { "itemid": "456" } |
DELETE /items/456 |
Source: Do you really know why you prefer REST over RPC